Big Tech Using Big Data For Perfect Prediction/Spying A Lie
Published on June 4, 2022 by Hemanth
--
The notion of big tech using big data to predict human behaviour has been an ethical concern for a while now. In 2012, one of the first controversial stories that highlighted this issue came to the limelight. A frustrated father walked into a Target retail store to complain about the fact that the retail giant had sent coupon codes advertising pregnancy/baby products to his teenage daughter.
The responsible manager was surprised to hear this complaint and apologized for the mistake. But later on, the manager received a call from the father. The father revealed that his teenage daughter was indeed pregnant and apologized to the manager for his earlier behaviour (source: Forbes).
You see, target had been using big data analytics models on their customers’ data. The end effect was that target was able to “know” that the teenage girl was pregnant before her own father. Fast forward to 2022 (the time of writing this essay), and it is not uncommon to hear people complain that they saw advertisements about stuff they mentioned in a casual conversation with friends at a party.
With the increase in connected artificial intelligence systems such as Alexa, Cortana, Siri, etc., people are getting more and more concerned about big tech using big data to know more about them than themselves!
In this essay, we will be covering some basic mathematics behind such big data analytics algorithms to see why they are overrated. Don’t get me wrong; I’m not saying that you should not be worried at all. But these models are probably not as clever as you think they are. This point will get clearer as you read along. Let us begin.
Big Tech Using Big Data for Pandemic Infection Prediction
Let us consider a hypothetical case where one of the big tech companies has developed a big data analytics algorithm to predict pandemic infection cases. For all we know, this might have actually happened in reality. So, I’d like to explicitly clarify beforehand that any resemblance of this hypothetical example to real-world events is purely coincidental.
Now, you may wonder why such a model would be necessary in the first place. Imagine an alternate reality where people are secretive about pandemic infections (for fear of some sort of penalty like quarantines) and a regulatory body has funded the development of such a model. Or the big tech company could be planning to sell the analytics information to a pandemic drug/vaccine manufacturer.
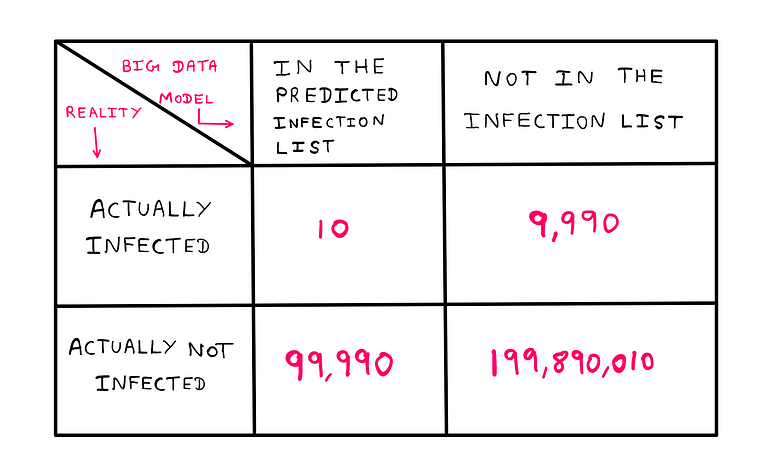
Now, let us say that the model is used on a population of 200 million people. Such a model would use the notion of “degree of confidence” to describe a potential infection. Contrary to what the typical person understands about big data analytics algorithm, they cannot predict with 100% accuracy. They always operate with a measure of confidence (probability based on statistics) that the prediction is true. In our case, the results of applying the model to a population of 200 million people would look like this:
Table created by the author
On the left half of the four-chambered number-square, we have the total number of people in the list predicted by the model to be infected. On the right half, we have the total number of people who are not on the list. The top half holds the actual number of people who are infected in reality, while the bottom half holds the actual number of people who are not infected in reality.
Analysing the Big Data Analytics Model
Now, imagine that you work at this big tech company and learn that your neighbour has made it to the list. You are concerned whether he could really be infected. That is, you wish to confirm if he belongs to the upper-left quadrant of the number-square.
The first thing you note is that of all the people who are on the predicted infected list (left half of the number-square), just 0.01% (10/100,000) are actually infected; in other words, almost nobody. On the other hand, of all the people who are actually infected, only 0.1% (10/10,000) made it to the predicted list. This means that there is a 99.99% chance that your neighbour is not infected.
Well, this looks like a shoddy model, right? Hold on. There is another perspective we are missing here. Let us say that you pose the null hypothesis that any given person is not infected. Given that the null hypothesis is true, what is the probability that this person would end up on the list purely by chance?
From the data we have, we see that a total of 99,990 people ended up by chance on the list. The total number of un-infected people was 199,990,000. So, the answer to our question is:
Probability that any given person would make it to the list by chance = 99,990/199,990,000 = 0.0499% (approximately).
Any un-infected person has only a 1 in 2000 chance (approximately) of being mispredicted. If we apply R.A. Fisher’s cut-off of 1 in 20 for statistical significance (for details, refer to my essay on how to really understand statistical significance), we could merrily reject the null hypothesis. This also means that we could state that your neighbour is infected with a chance of misprediction of 0.05%.
Surely, this poor big data model cannot be how actual big tech companies operate, right? Well, let us see what the reality has to say.
Big Tech Using Big Data — A Real World Example
In 2006, Netflix held a competition with a prize of $1 million challenging the participants to develop a recommendation algorithm that performed 10% better than Netflix’s own algorithm at that time. For this purpose, the participants were provided with a huge dataset of about a million anonymized ratings for 17,700 movies.
It took three years before anyone beat Netflix’s algorithm by 10%. And in order to do this, several teams had to band together their pretty good (but not good enough) models. Even after all of this, Netflix did not end up using the winning algorithm.
Why? Because by the time the new algorithm came up, Netflix was transitioning from DVDs to online streaming. And in the world of online streaming, poor recommendations are not as big a deal as with physical DVDs.
This story has a lot of important details about how big tech uses big data to predict human behaviour. Firstly, why was Netflix willing to pay $1 million for an algorithm just 10% better than its own? The answer is that in the big data analytics prediction market, a 10% improvement over the state-of-the-art is worth a lot of money (a lot more than $1 million).
Secondly, why did it take competitors three years to crack the problem? The answer is that this is a very hard problem that involves a lot of resources to solve. Besides, even after the improvement, the truth is that there exist hard limits on how well such models can predict using statistical/probabilistic methods.
So, what’s the deal here? What is the thread linking the Target story, our hypothetical example, and the Netflix story? Let’s get to that next.
Big Tech Using Big Data Struggles with Fat Tails
The fundamental difference between our hypothetical example and the Target/Netlfix stories is that the former deals with relatively rare events, whereas the latter deals with relatively frequent events. Without going into cumbersome technical details, I’ll just say that the rarer the event we are trying to predict, the less useful big data analytics tends to be.
Let us say that in our hypothetical example, the big tech company pools in a lot of resources to double the accuracy of the prediction model. Doubling a very, very small number still results in a small number. It just transforms a ‘very bad’ model into a ‘bad’ model.
One of the real-world companies that is attacking this class of problems very innovatively happens to be Palantir. Palantir originally aimed to solve the problem of predicting criminal activity (among others) using big data analytics. According to Peter Thiel, their breakthrough came when Palantir implemented an augmented ‘big-data-plus-human-expert’ approach.
Because of sensitive nature of these problems, it is hard to get proof of efficiency of Palantir’s models. Even assuming that they are as good as their makers claim them to be, it is clear that big data on its own has its limits. So, what does all of this have to say about big tech spying on our day-to-day lives?
Big Tech Using Big Data for Perfect Prediction/Spying is a Lie
To be fair, our hypothetical example is not representative of the state-of-the-art in terms of big data analytics. With the advent of machine learning & co., big data analytics algorithms have been steadily improving over time. With all that being said, our hypothetical example highlights very well the inherent issues with big data analytics algorithms, especially how they struggle with fat-tailed rare events.
“So what? That just means that these models predict correctly most of the time. So, they actually ARE very good at prediction.”
If you are thinking along these lines, I’d argue that you are mistaken. You see, rare events are much more common than you or I would like to intuitively admit. One single rare event is, by definition, rare. But SOME rare event happens to someone, somewhere, ALL the time.
Given the same set of circumstances to the same human being, the said human being has the potential to disrupt the observed pattern on any single occasion (thus defining a rare event). Such is human behaviour; inherently chaotic and hard to predict.
If you wish to fact-check in real life, go to any business owner who bought advertisement services from Google or Facebook and ask him/her how well those models worked. You’d be surprised to hear how goofy they are. Why go even that far? When was the last time you were frustrated with a Netflix/Amazon recommendation? I bet that it occurs more often than you’d like to admit.
Final Remarks
To conclude, your ‘smart’ artificial intelligence companions: Alexa, Siri, Cortana, etc., are in the business of out-predicting their competition just by enough of a margin (say, 1%) so that they can corner, say 10% more of the advertisement market. Such services are not in the business of perfectly predicting your next step.
Even if they wanted to, current approaches are incapable of predicting every aspect of human behaviour. The notion of big tech using big data for perfect prediction/spying is a lie!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.

Comments