I recently came across a highly fascinating mathematics experiment out there in the wilderness that is the internet.
The whole situation started with the following probability-based poll:
A bag contains 10 balls.
7 balls are red.
3 balls are green.
You draw one ball out without looking. What is the colour of the ball you just drew out?
On the surface, this question appears charmless. If we define ‘R’ as the event that the ball you drew out is red, then P(R), the probability of this event occurring, would be 0.7 or 70% (since there are 7 red balls).
Consequently, the probability of the event that the ball you drew out is green, P(G), would be 0.3 or 30% (since there are 3 green balls). So far, so good. There is arguably nothing special about this exercise. But that is only until you look at the results of the poll.
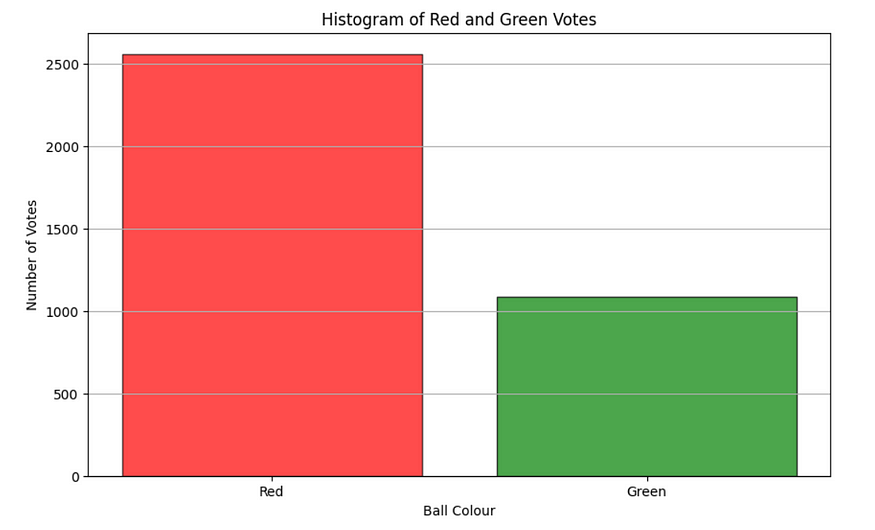
A total of 3645 people voted on this poll, out of which 75.3% chose red and 24.7% chose green. A random internet stranger was fascinated that the poll results resembled the actual probability ratio.
Ball Colour Vs. Number of Votes — Histogram created by the author
In their further investigation, they noted that similar polls exhibited a similar characteristic wherein the poll results resembled the actual probability splits of the underlying question/event.
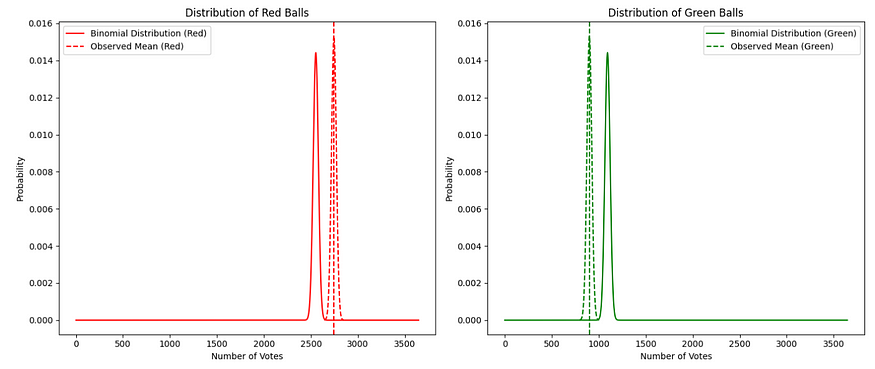
This is when I came across this experiment. But I noticed a much more interesting phenomenon (to me). While it was true that the poll results resembled the underlying probability split, I noted that the votes were consistently biased (with varying degrees of slightness) toward the more probable event.
The voters were consistently over-estimating the probable outcome as a group. This got me thinking.
Distribution of red balls vs. green balls — Binomial distributions created by the author
Why does this occur? And what does it mean in our day-to-day lives?
These are the questions that I will be answering in this essay. It just so happens that I have practical experience with this phenomenon, which lets me share potentially useful insights with you as the reader.
Mental Math at its Finest
Human beings are simple creatures; most of us seldom over-complicate things. Unlike school and university where we get 15 minutes to solve a complicated probability-based question, in real life, we are often forced to make split-second decisions with huge payoffs or losses.
How do we do this? Well, it is largely thanks to the biases and heuristics we develop from our life experiences. These natural “shortcuts” enable us to make split-second decisions based on situations we observe and experience. Obviously, they come with a drawback.
Although they are useful most of the time, they cost us dearly on a few occasions. Before I go into why this is, let me elaborate on a couple of biases/heuristics in life so that you may orientatate yourself with what we are dealing with here. Pay close attention to the following scenario, which we will be revisiting later in the essay.
Imagine that you hear from a neighbour that they are suffering from food poisoning after eating at a local restaurant. When you hear this, you share the bad news with your family and expressly declare that none of you will be visiting the said local restaurant.
When you ask your neighbour what convinced them to visit the restaurant, your neighbour shares that on the three occasions they walked past the restaurant, they noted the staff were all dressed professionally and seemed organised and reliable.
Furthermore, when they looked at the menu card, the high prices seemed to suggest that this was a high-class restaurant. At this price range, the food is typically made from high-quality produce sourced locally.
Now, you might be wondering what all this has to do with probability. Why don’t we lock the pieces of the puzzle into their places next?
The Human Side of Probability
Let us first focus on your decision to not visit the local restaurant under scrutiny. Just because your neighbour is suffering from food poisoning after visiting the restaurant does not mean that the restaurant is to blame.
In other words, although the probability is high that the restaurant caused the food poisoning, it is certainly not 100% (expressed as truth in common words).
Furthermore, even if the restaurant is to blame, you would not be eating the same meal. Chances are that you might be visiting the restaurant on another day at another time. Based on these factors, your probability of suffering from food poisoning is reduced significantly.
But if told you this and encouraged you to visit the restaurant, you might respond like so:
“Are you out of your mind? Now is not the time to be specific about the numbers. I would rather not take the risk!”
If this is indeed you, I would completely understand. In fact, this is a natural response. What is going on here is that you are overestimating the probability that you will get sick if you visit the said restaurant.
There are a few heuristics/biases in play here, but the most prominent one is the recency bias/heuristic. Since the incident with your neighbour happened “recently”, your instincts are wired to overestimate the probability and minimise risk at all costs.
Although your mental math of the probability is wrong here, the outcome is arguably a good thing, as you are protecting yourself against the risk of food poisoning. What is the alternative? Well, you eat at home and are significantly less likely to suffer from food poisoning. It makes sense to take that alternative, given the risky option.
Next, let us focus on what convinced your neighbour to visit the said restaurant. On the three occasions that they walked past the restaurant, they noted that the staff were all dressed professionally and seemed organised and reliable. The key word to note here is “seemed”.
This word compares the attire and behaviour of the staff. The question is with “what” does it compare these qualities? The implicit point here is that your neighbour has built a mental model of various kinds of restaurant staff based on what they wear and how they behave. Based on their mental “average”, what they saw “seemed” to suggest that this restaurant featured professional and reliable staff.
This is a manifestation of the representativeness heuristic, wherein people rely on stereotypes to make quick decisions. We don’t always have the time to sit and chat with people to figure out if they are professional or not. Most of the time, we pay attention to their behaviour and attire and match them against a mental “stereotype” we have built over the years. And most of the time, it works in our favour too! It just happened that the heuristic misfired in your neighbour’s case on this occasion. The price? Food poisoning!
Man Vs. Probability — Illustrative art created by the author
If you remember though, your neighbour did not merely make their decision based on representativeness, but also the prices in the menu card. In their head, they related such high prices with high-class restaurants they had been to in the past. In such restaurants, the food is typically made from high-quality local produce. This is a classic manifestation of the anchoring heuristic, where you anchor certain emotions or thoughts to certain numbers. Low price = low quality; high price = high quality.
You see the problem here already, don’t you? But wait, the truth is that both you and I are guilty of this, and the even more counterintuitive fact is that this heuristic is more useful than it is not. Parents seldom purchase cheap plastic toys for their children; children chew on that stuff on occasion. It makes sense to invest the money and go for a more trustworthy brand.
In this case, though, your neighbour unfortunately drew the short end of the straw.
Now that we have touched upon heuristics and biases and you have an idea about what we are dealing with here, let us head back to the poll.
The Bias Behind the Odds
In case you don’t remember what the poll was about, let me jog your memory:
A bag contains 10 balls.
7 balls are red.
3 balls are green.
You draw one ball out without looking. What is the colour of the ball you just drew out?
A total of 3645 people voted on this poll, out of which 75.3% chose red and 24.7% chose green. I noted that the poll is slightly biased (by about 5%) towards red, which is the more probable outcome.
Why is this? Well, a variety of heuristics and biases might be in play here. You might vote for red just because many before you have voted for red (confirmation bias). I, having noticed that the vote ratio is different from the probability ratio, might vote for green to nudge it back towards what I think the vote ratio should be (anchoring).
Someone else might be plain overconfident about their understanding of probability. The possibilities are many, but even considering all of this, the net outcome is that a group of voters is likely to collectively over-estimate the odds of the event being red.
What are the Consequences of Group Think Biases in Probability Estimations?
Imagine that you wish to purchase a new property. The general consensus is that the probability that the price of this property will go up in the future is high. Therefore, the entire group of potential buyers overestimates the current price of the property (similar to the poll results). As a result, you end up paying more than what the property is actually currently worth.
Do you have a choice? Well, I would argue that you do not have much choice, at least when it comes to this property. You cannot act against a mob moving in consensus, after all. In fact, many brokers and middlemen take advantage of this phenomenon and shave some of the over-estimation from either side.
Having said that, there is something else you could do — the exact opposite. Instead of moving with the mob, you could look for a deal where the mob collectively underestimates the probability of the price going up, and thereby, bids a lower price. Like before, a group needs to overcome a lot of resistance to move the price. This takes some time. As an individual, you could just walk away with a reasonable deal in the meantime.
The bad news is that this is what scalpers do. So, on the one hand, you deal with brokers and on the other hand, you deal with scalpers. In my experience, it is worth the effort to go against the scalpers. It is not easy, but it is “easier” compared to moving against a mob acting in consensus.
Since I mentioned “property”, you might have anchored yourself on certain numbers. Just so that I get my point more objectively across, let me clarify that this behaviour affects anything sold and bought in the free market. This could range from trading cards to washing machines.
I have found quite interesting applications for this thought process (paired with quantitative analyses) in the stock market, to source undervalued videogames in the market (I collect them), etc. This typically involves aggressively passing on deals that appear sweet on the surface, but are still in consensus with the crowd; telling them apart is the hard part. Once in a blue moon though, I spot a good deal backed by the data and sometimes, I get there before the scalpers do.
If you pause to observe, you will notice certain trends in markets. Once you observe trends, you might notice some gaps.
All you need to do is pause and observe before you act — easier said than done. If it were easy, everyone would be good at it!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.

Comments