How To Solve The Mystery Of The Oscillating Function
Published on May 5, 2022 by Hemanth
--
What is so mysterious about an oscillating function? You see, I had originally written an essay on how to solve a tricky algebra problem. This problem involved a rational function with an unknown exponent (x) on the left-hand side (LHS) and the constant ‘2’ on the right-hand side (RHS). As per the challenge, the unknown variable could only take integer values (the solution turned out to be ‘x = 1’).
However, post publishing, reader Willem van der Zwart expressed his curiosity about what the solution or approach would look like if we allowed for rational and/or irrational numbers as solutions as well.
“But what if x is allowed to be a rational or even irrational number?”
How the Mystery of the Oscillating Function was Born?
Quite instinctively, I plotted the function for a range of input values and deduced that there were two solutions: one at ‘x = 1’ (as before) and one at the limit of zero.
When I shared a plot that showed this behaviour, Willem curiously plotted the function on his own using an online graphing tool. He went onto to zoom in on zero and noticed that the function appeared to be oscillating between positive and negative values.
“If you zoom in on 0, it looks like the function is oscillating between positive and negative values when approaching x=0, for example zooming in at -0.0000001 and +0.0000001.
Although this might be an artifact of the Graph plotter due to rounding errors, it could perhaps also mean that there are an infinite number of solutions in this area.”
Thus, the mystery of the oscillating function was born. I had to jump in and figure out what was going on.
The Hunt for Answers
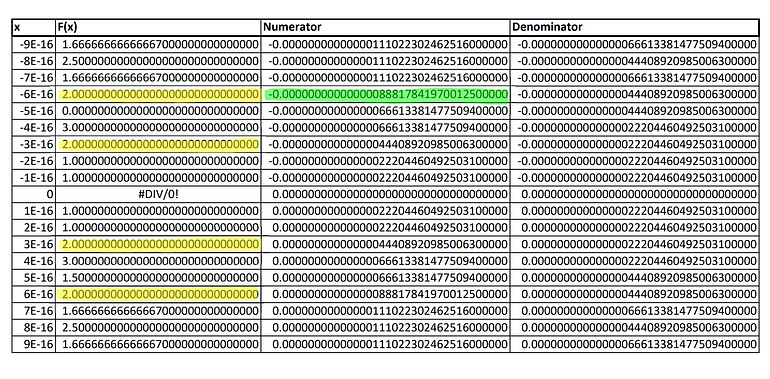
The very first thing that I did was to recreate the oscillation in my local worksheet. After confirming that it was indeed the case, I calculated the output values of the function for inputs values in the range of -9E-16 to +9E-16:
Worksheet table created by the author — showing function outputs for inputs ranging from -9E-16 to +9E-16
You can see that the RHS of the original equation (2) appears multiple times in this domain. Could it be that we have more than two solutions to this equation if we allowed for rational/irrational numbers? Well, I wasn’t convinced. I thought that there was something fishy about this result. So, I decided to investigate further.
I started by investigating the individual components of the equation’s LHS — the numerator and the denominator. The results from my worksheet came out as follows:
Worksheet table created by the author — showing individual components (numerator and denominator) of the function for the inputs mentioned above
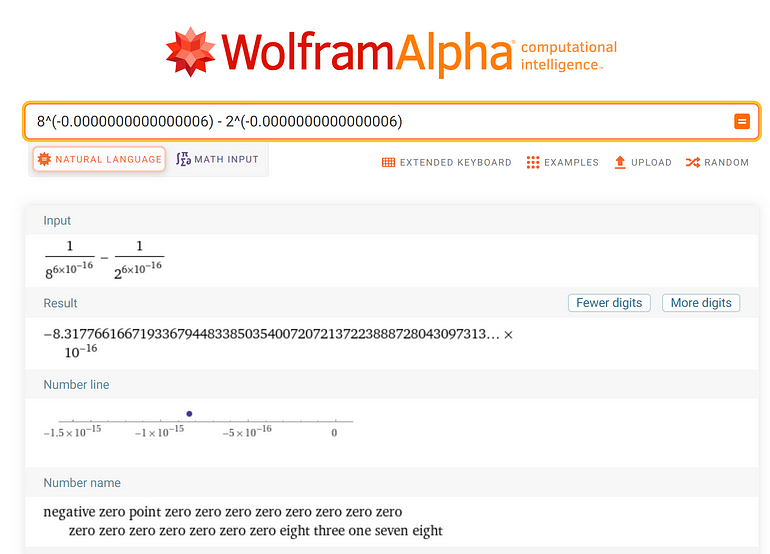
To check if there was some sort of accuracy error happening here, I focused on the value of the output’s numerator for the input of -6E-16 (highlighted in green in the image). Next, I performed the same calculation using Wolfram Alpha and got the following result:
Screenshot captured by the author (calculation courtesy of Wolfram Alpha)
As you can see, not only is the result markedly different, but the number of significant digits is much higher than what my worksheet calculated. Just what is going on here?
How to Solve the Mystery of the Oscillating Function
As it turns out, such issues are quite common in the programming world. But alas! I’m no programmer (at least, not by trade). What Willem and I had stumbled upon were the limits of double precision floating point numbers.
In most modern computers, mathematical concepts are implemented using digital logic. Some of these computer science concepts perfectly represent the corresponding mathematical concepts and the end-user need not know about their inner workings. However, some of these computer science concepts are leaky abstractions of the corresponding mathematical concepts; they start breaking down at their limits.
One such leaky abstraction is the concept of floating-point numbers. We think that they are equivalent to the mathematical concept of real numbers (which they are for the most part). But they are not always equivalent to real numbers. To begin understanding what is going on with our function, we need to understand how floating point numbers work.
How Do Floating Point Numbers Work?
A double-precision floating point number uses 64 bits of information and is expressed in the following form: +- p*2^e (according to IEEE 754).
The first bit holds the sign (+ or -; 0 for positive and 1 for negative), the next 11 digits hold the value of the exponent (e), and the remaining 52 digits hold the value of the precision (p). The 11 digits that store the exponent do so with a bias of 1023. This allows for exponents in the following range to be expressed: -1023 to + 1024.
What is important to note here is that the two exponent positions of (e_min — 1) and (e_max + 1) are reserved for special uses — to handle limits and to de-normalize binary numbers. We will skip the normalization part in this essay as it is not directly relevant to our problem.
The special exponent that is one lower than e_min is used to represent 0 (among other functions), whereas the special exponent that is one bigger than e_max is used to represent infinity and NaN (Not a Number).
What all this means is that the remaining 52 bits are capable of handling the following limits:
1. Since the largest exponent is 1023, the largest real number that a floating point number can handle is approximately equal to 1.8 * 10³⁰⁸ (defined as DBL_MAX in C). If you wish to check this limit, try calculating the factorial function output for 170 and 171 on your computer. Most modern computers are limited to this level.
2. The smallest positive real number that a floating point number can handle in its normalized form is approximately equal to 2.2 * 10^-308 (defined as DBL_MIN in c).
3. The smallest positive real number that a floating point number can handle in its denormalized form is approximately equal to 4.9 * 10^-324.
If we attempt to represent any smaller number using floating point numbers, it will underflow to zero. This is why floating point numbers are practically considered to possess between 15 and 16 digits of precision as far as decimal places are concerned.
The Culprit Behind the Oscillating Function
The culprit with our function is the subtraction operation (or the addition of two numbers with opposite signs) — both in the numerator as well as the denominator. With floating point numbers, if two numbers match up to the n-th decimal place, we could lose up to n digits of precision when we subtract one of these numbers from another.
This is what is essentially going on when I plot output values of the function for inputs values in the range of -9E-16 to +9E-16. Since the numbers (in both the numerator and the denominator) are of the same order, errors (loss of precision beyond 16 digits in the floating point numbers) of very small magnitude in the input lead to very large errors in the output.
In short, the errors create garbage output (noise).
Final Thoughts
Ifyou are a programmer, the contents of this essay are probably fundamental knowledge to you. But I am an end-user (mostly), and I bet that I am not alone. I can imagine people who deal with extreme numbers (such as in the fields of probability theory and statistics) facing this challenge where the output does not make sense.
It is not very often that end-users need to take jump into the inner workings of computational concepts — this is one such a case. As far as Wolfram Alpha is concerned, I do not know of how their algorithm works, but their model is capable of handling numbers up to any arbitrary level of precision.
Screenshot captured by the author (courtesy of Wolfram Alpha)
If you are wondering about the solution to the original equation, I confirm my initial deduction that there exist two solutions — one at ‘x = 1’ and one at the limit of zero.
As a final note, I’d like to thank Willem van der Zwart for showing curiosity and leading me into investigating this topic.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
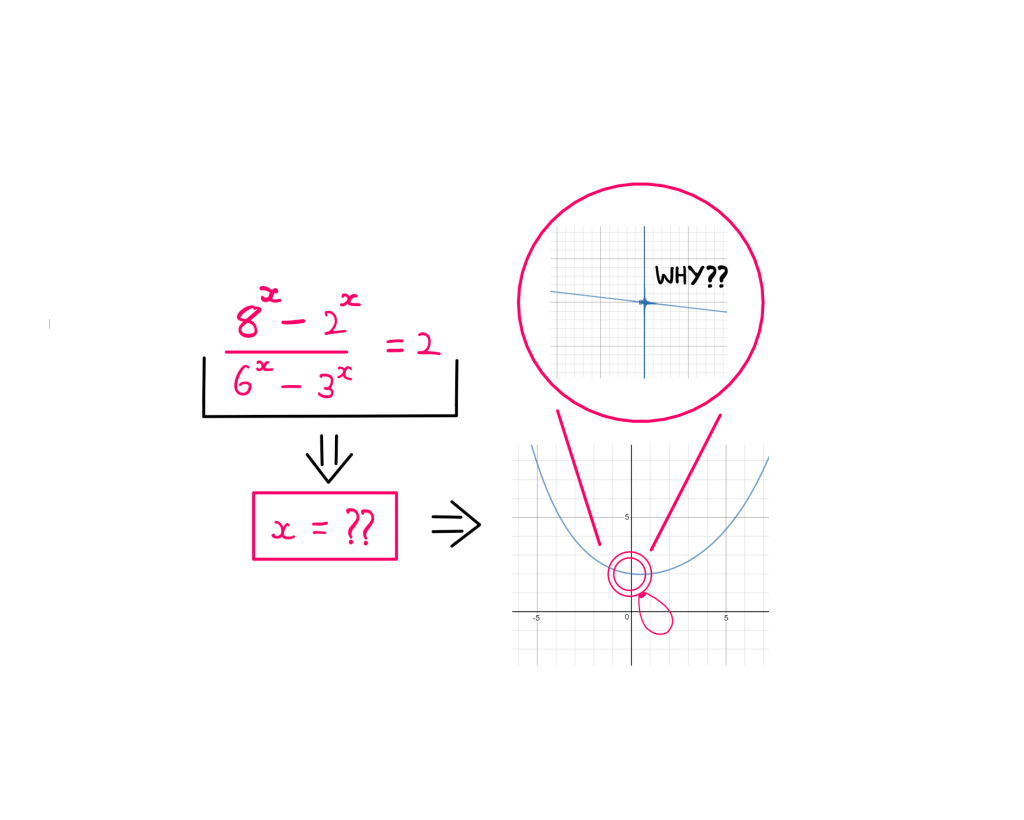



Comments