How To Really Understand The Mathematics of Language?
Published on March 8, 2022 by Hemanth
--
What does “Mathematics of Language” mean? Before we approach that question, what do languages and mathematics have in common?
Well, let’s start with a practical experiment to establish the relevance of these questions first. Try to read the following sentence:
Image created by the author
If you are a native English speaker, you were most probably able to read the above (enciphered) sentence. This essay covers how this phenomenon connects our language usage to mathematics, and how we can benefit from this connection.
Let’s start with analysing what is going on with the above-enciphered sentence.
If you were perceptive enough, you would have noticed that I just replaced all the vowels in the English language with a triangle symbol in the enciphered sentence. So, in order to make sense of it, all you had to do was to “guess” the missing vowels correctly.
So, in essence, we just established that we can still make sense of a sentence even if we take the letters (in this case, the vowels) out of words. If you are still sceptical about this “claim”, let’s test it one more time using SMS-lingo:
If we can communicate more efficiently using lesser letters, why do we still use long-form sentences with complex grammatical structures and rules? To answer this question, we need to understand Shannon entropy first.
Claude Shannon: The Underrated Genius
Claude Elwood Shannon is, in my opinion, one of the most underestimated science figures of all time.
As a 21-year-old master’s degree student, he single-handedly defined the fate of an entire branch of science (now known as information theory) in his master’s thesis.
Not only did he ask ground-breaking questions in his thesis, but he also went on to provide most of the answers as well. Usually, such progress in science happens through a series of minor innovations over decades. But Shannon made a discrete jump possible, which led to the digital computer revolution that we still enjoy today.
From computers to smartphones, Shannon’s revolutionary master’s thesis is still being used in our current technological devices. On a personal note, some of my own technological innovations have been inspired by Shannon’s work. Needless to say, he is one of my all-time heroes!
Among all of his influential contributions, two notable ones are relevant for our current purposes:
1. Development of Shannon entropy as a measure of information content in a message.
2. Prediction and entropy of printed English (reference link at the end of the essay).
Shannon Entropy
Shannon defined information entropy (known as Shannon entropy) as a measure of the amount of information that could be transmitted by a message. To understand this further, let us take an intuitive approach rather than look at the mathematical formulation.
Let us consider a coin that features “heads” on both sides. Now consider this as an information system. We are interested in the least number of questions we need to ask to ascertain the state after a toss.
When we toss such a rigged coin, regardless of whichever side comes on top, we know that the outcome would be “heads”. Therefore, no question is necessary. According to Shannon’s approach, such a message system has zero entropy.
Now, consider a fair coin with “heads” on one side and “tails” on the other side. If we toss the coin twice, what is the least number of questions we need to ask to ascertain each substate? The answer is two — one for the outcome of each toss.
According to Shannon’s approach, such an information system would carry two bits of entropy. A “bit” here is a measure of information. That’s right — it was in Shanon’s master thesis that the term “bit” was expressed for the first time. Shannon attributed the usage of the word to fellow mathematician, John Tukey.
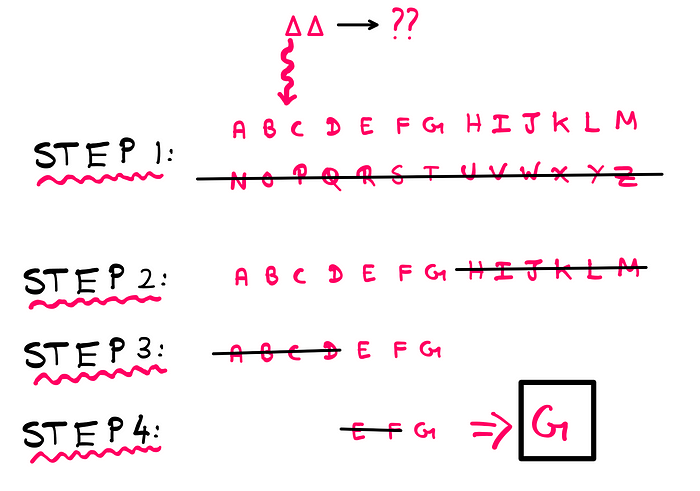
Now, consider a two-letter English word whose alphabets are not known. What is the least number of questions that we need to ask to ascertain the word? Well, what if we use the following approach?
Question: Does the first letter belong to the first half of the English alphabet or the latter half?
Based on the answer, one could repeat the process to ascertain the letter:
Image created by the author
In this example, we were able to ascertain the state using 4 steps. This also means that this information system contains 4 bits of entropy. To save us some effort, let us say that we figured out that the second letter was “O” using 5 steps. Therefore, the word “GO” contains 9 bits of entropy.
Order and Randomness
You see, the word “GO” contains 9 bits of entropy only if you consider the occurrence of the English alphabet as a random variable.
However, the English language conveniently features order in the form of grammar and other conventions. A few examples of the order are the following:
1. The letter “E” appears much more often than “Z”.
2. The letter “Q” is highly likely to be followed by the letter “U”.
If you think this is fascinating enough, not only did Shannon take notice of all this, but he dove deeper! Through the application of statistics and experimentation, he recorded patterns and calculated the entropy of the English language to be 2.62 bits per letter on average.
Now, where do we go from here with this knowledge?
The Mathematics of Language: Redundancy
Shannon was interested in using these results to develop models of prediction and compression for information transmission (in the English language). In a sense, he wanted to maximise entropy available in a given bandwidth architecture.
Broadly speaking, most natural phenomena exhibit a trend where entropy only increases with time (empirical observation). Rather paradoxically, the history of the English spelling system suggests that we are moving from higher entropy to lower entropy over time.
This is because human beings (and nature) have slightly different intentions. It appears that whenever the importance of a message increases, we prefer to use long formulations with many redundancies packed into the text. With such an architecture, we make sure that even if a few letters or words are missed, the core of the message is still held intact.
For example, consider a case where you are texting your best friend to plan a party and another case where you are writing an application for your dream job. In the former, you are likely to use compressed short messages, whereas a job application demands a lot more attention to detail. This in turn leads to more redundancies in the language used for the dream job application.
Filling In the Blanks
The highly redundant nature of the English language combined with our cognitive pattern-seeking nature is what enables us to comprehend sentences even when vowels or letters are taken out.
As serial optimisers, we might think that there is room for more efficiency to be gained in our usage of the English language. But historically speaking, the evolution of the language has been in the exact opposite direction.
The gradual increase of structural redundancy has made English easier and easier to use over the past decades and centuries. This in turn has made the language significantly more resilient to errors in communication and robust in usage. It is then no wonder why English has thrived as a Lingua Franca across the globe over time.
Final Remarks
Have you ever wondered why a scratched Compact Disc (CD) works fine most of the time? It is because CDs have redundant bits and error correction protocols encoded onto them. In this way, they are more resilient to errors. So, the rabbit hole goes beyond just the English language.
The moral of this essay is that not everything is worth optimising for efficiency. Sometimes, resilience to error and robustness are of higher priority than just blind efficiency!
I hope you found this article interesting and useful. If you’d like to get notified when interesting content gets published here, consider subscribing.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
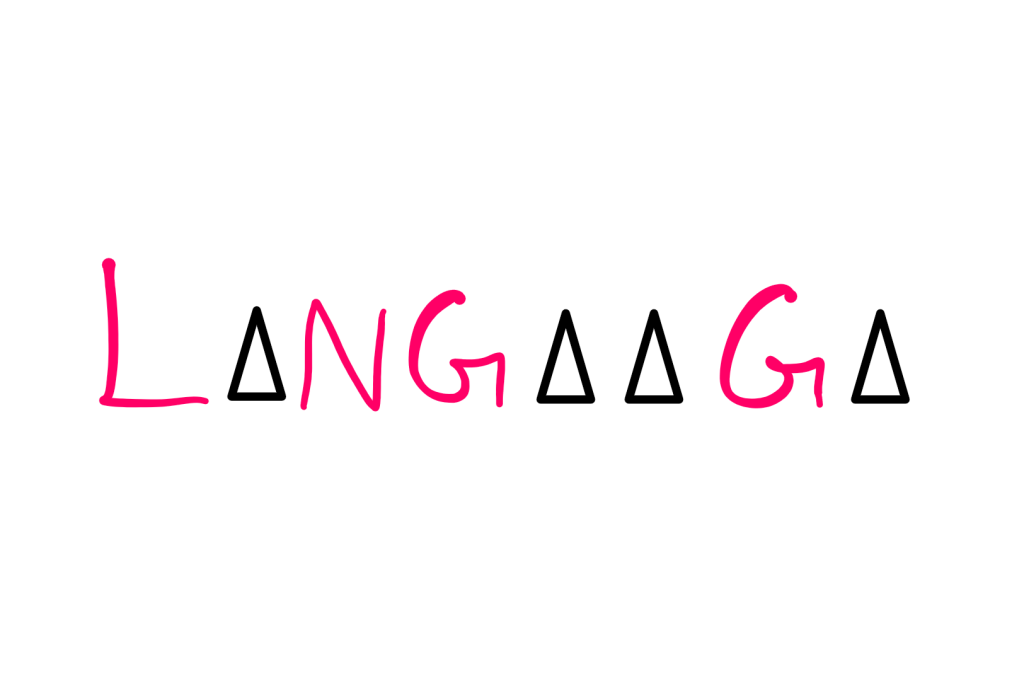
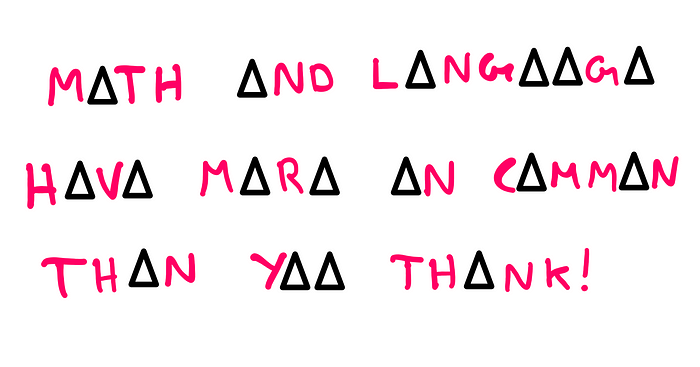


Comments