How To Really Avoid P-Value Hacking In Statistics?
Published on May 24, 2022 by Hemanth
--
P-value hacking is a phenomenon that is currently ensuring that most published statistical research findings are false. In my essay on statistical significance, I briefly covered what a P-value is.
In this essay, we will first do a quick recap of the statistical method and what the P-value means. Following this, we will proceed to see how P-value hacking occurs and what its direct consequences are. Finally, we will explore solutions to the problem at hand. In our ever-so-increasingly data-driven world, everyone would benefit from awareness and knowledge of this topic.
The Statistical Method — A Recap
The modern statistical method can be summarized in the following steps:
1. Formulate the null-hypothesis.
2. Conduct an experiment and record observations/data.
3. Calculate the probability of obtaining the observed results as exceptions (extremes) to the null-hypothesis, assuming that the null-hypothesis is true. This probability value is known in the biz as the p-value.
4. If the p-value is less than a threshold value, it means that your experimental results reject the null-hypothesis, and consequently, are statistically significant. If the p-value is above the threshold value, then it means that the null-hypothesis has not been rejected.
As a reminder, the null hypothesis is framed in such a way that it describes the hypothesis that you would like to reject/discredit. R.A. Fisher was one of the foremost pioneers of the modern statistical method. He preferred a threshold p-value of 0.05, and the convention stuck.
If all this information is too abstract for you, let us go through a quick example. Let us say that you are conducting a statistical experiment to see if a drug has the intended effect.
The corresponding null hypothesis is that the drug has no effect. Once you have the experimental results, you calculate the probability that your observed results would be the case if the drug were to indeed have no effect (due to luck). This probability value is the p-value.
A very low p-value (say, below Fisher’s 0.05) suggests that the probability that the observed results occurred purely by chance is very low. So, it boosts your confidence that the drug indeed has the intended effect. So far, so good.
Before, we move on to the issue of p-value hacking, it is beneficial to cover the issue of confidence hacking first.
The Philosophy of Statistics — The Issue of Confidence Hacking
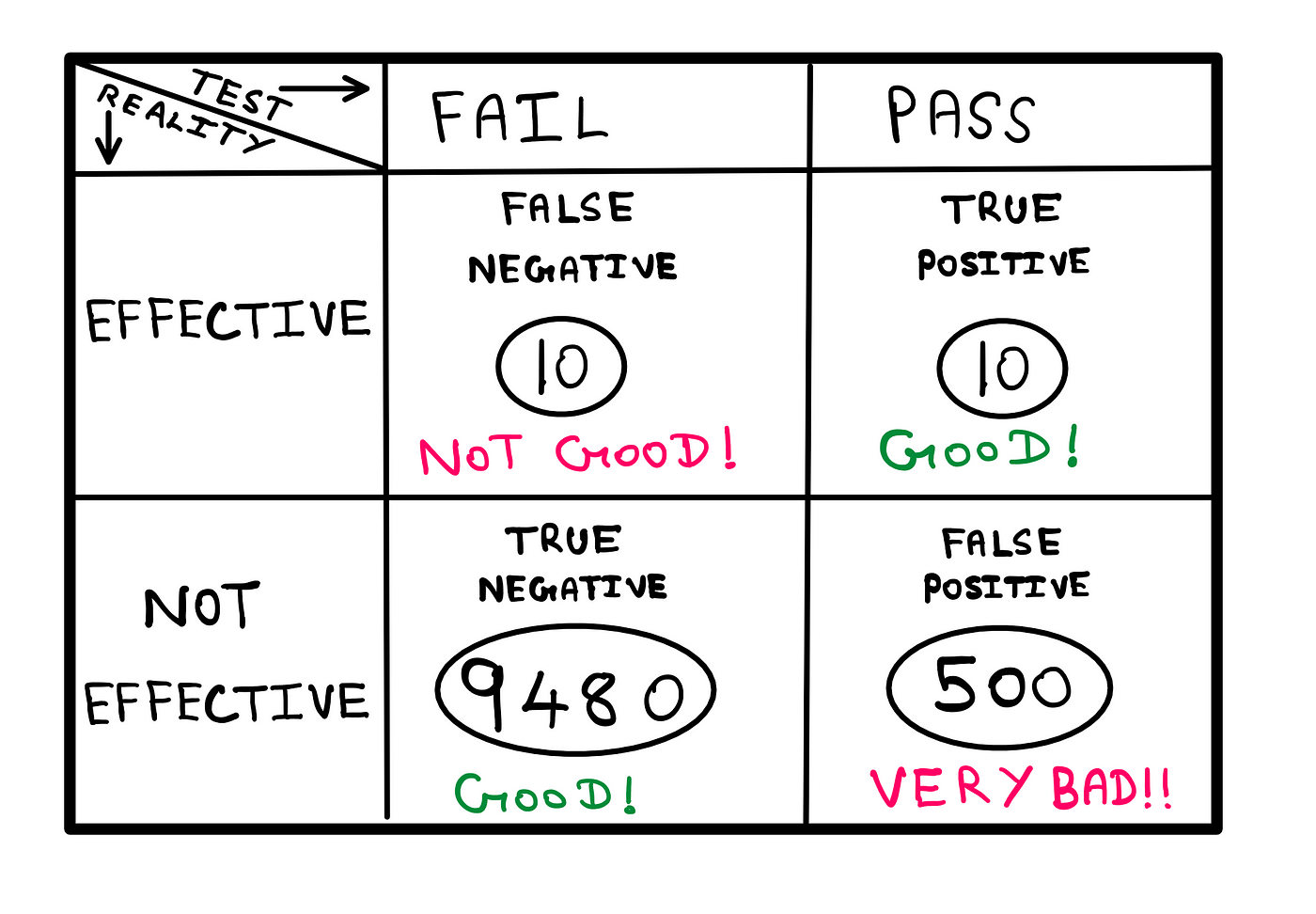
Say that you are conducting a statistical analysis that correlates 10,0000 different organic ingredients with positive effects on human beings. Let us say that in reality, 20 of these ingredients truly have an effect (though we don’t know this at the time of the study).
After applying Fisher’s recommended p-value filter of 0.05, we end up with the following results table:
The Statistical Analysis Results Table — Created by the author
Out of the 20 ingredients that truly have a positive effect, 10 don’t make it past the 0.05 threshold (top-left corner). This is not good; but it is to be expected. The remaining 10 out of 20 ingredients that truly have an effect are correctly categorized as true positives (top-right corner).
Clearly, most of the ingredients that don’t have an effect are rejected by the analysis. This is a good thing, and is also to be expected (bottom-left corner). Finally, we have on the bottom-right corner, 500 ingredients that have no effect falsely classified as ingredients that have a positive effect. This is very bad. Still, this is ALSO to be expected. Even though the number is 500, it is within what the p-value threshold promises to reject/allow.
In short, we have ended up in a situation where we have statistically significant results that give us very little confidence.
The principle of confidence hacking works as follows:
If “p < 0.05”, then the null hypothesis must be false. If “p > 0.05”, then the null hypothesis must be true.
Basically, the issue of confidence hacking treats the p-value filter as a hard truth-criterion (which it is not). If you wish to read an in-depth discussion on this topic, check out my essay on the philosophy of inferential statistics. But for now, let us move on to the main topic of this essay.
What is P-value Hacking?
P-value hacking is a special case of data manipulation when the p-value is right on the limit of being statistically significant (for example, p = 0.06). The biggest offenders in this domain are modern scientific researchers.
Say that a scientific researcher has been researching on a hypothesis for the past 3 years. Finally, after gathering the funds to conduct a proper experiment, she sets off to work on the numbers. The statistics reveal that the p-value is 0.059 (for statistical significance p needs be lesser than 0.05 in her case).
After three years of hard work, the researcher is facing a situation where it might all end-up meaningless. She goes through all of the data sets.
“Did I over-weight the pressure factor? Did I “by mistake” exclude any outliers in the data? Did I “by mistake” include any outliers in the data?
Okay, what happens if I remove these five data points? Wow, the p-value is now down to 0.041. Right, that settles that.”
Would you blame the researcher? I would not. We all know of the teacher who gives away a couple of mercy points to her students who are on the verge of failing. If two points are going to pass them, what’s wrong with giving the points away? Scientific Researchers are human beings, just as teachers are.
Blame the system; don’t blame the players.
Even though I am empathetic to the researchers, small manipulative mistakes do add up. In 2005, John Ioannidis published a paper titled “Why Most Published Research Findings Are False” (linked in the references section at the end of the essay).
In this paper, he critically showed how such minor rule-bending adds up to catastrophic systemic consequences. Science involving statistical methods (especially social science) has become less trustworthy over the years.
How to Really Avoid P-Value Hacking in Statistics?
The issue we are facing here is systemic. So, it makes sense that the solution(s) be systemic as well. Firstly, there seems to be an asymmetry as to how statistical results are being handled. Currently, most science publications are interested in publishing “statistically significant” studies/research.
Research with statistically insignificant results goes in the back-office drawer, only to be never seen again. This leads to two issues:
Firstly, the rest of the world does not know about the “failed” experiment/study. So, other researchers are bound to repeat the same experiment/study until the writing is on the wall for the entire community. This leads to the wastage of precious resources.
Secondly, researchers are incentivized to “cheat”. If a human being is punished for not p-value hacking and rewarded for p-value hacking, can you really blame the human being for his/her actions?
Publications need to start incentivizing statistically insignificant research results as well. This is not a silver bullet, but it is a start!
Fisher once wrote:
“A scientific fact should be regarded as experimentally established only if a properly designed experiment rarely fails to give this level of significance.”
– R.A. Fisher.
In short, even after a statistically significant result is published once, it could be purely by luck. So, publications also need to promote and publish follow-on research work that aims to reproduce results from first-time research. You’d be surprised to know how many studies are not reproducible or were purely due to luck.
Final Thoughts
To conclude, p-value hacking is rampant, and the situation is dire. However, the statistics community is already aware of the issue and is slowly taking action to resolve it.
As an end-user of statistical products in our data-driven world, it is immensely beneficial for you to be aware of the p-value hack.This enables you to ask the right questions before you make critical decisions!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.

Comments