Reinforcement learning is a key branch of machine learning that finds applications in many fields. At its core, reinforcement learning focuses on modelling intelligent agents as algorithms. These agents in turn aim to make decisions in their environment(s) that maximise cumulative reward.
Reinforcement learning is an actively growing field where mathematics and computer science integrate to produce practical results. The growth of computational power over the years has certainly helped the cause of reinforcement learning.
However, as I was researching this topic most recently, I came across a science project that bucked the trend and followed a very unique approach. In this project, scientific researchers chose not to employ computer science to execute reinforced learning, but behavioural psychology instead.
That’s right. We are talking about applying reinforcement learning algorithms to real-life intelligent agents. If you think about it, such an approach goes back to the roots of learning algorithms and epistemology. In this article, I aim to cover the details of this unique project and touch upon what implications such an approach might have on the further development of reinforcement learning as a field.
When it comes to identifying cancers in general, Pathology and Radiology are two fields that play a key role. There are constant developments of new automated technology in both Pathology as well as Radiology.
In order to test such new technology, the medical device manufacturers need access to expensive pathologists and radiologists. Such experts supervise and accompany the development process of the latest technology until it meets the stringent norms to be classified as market-ready.
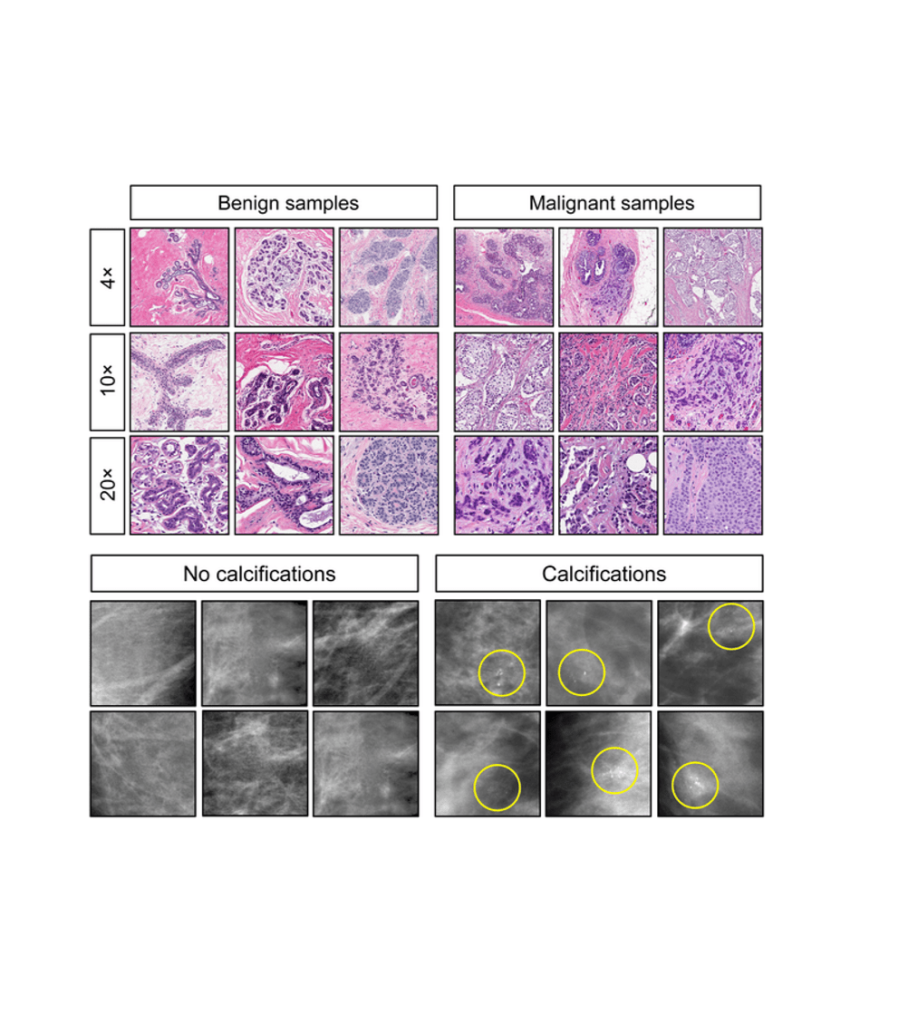
A team of researchers set out to see if non-experts could be trained using reinforcement learning methods to produce comparable results in pathology and radiology. For this purpose, they chose histological and mammogram images related to cases of breast cancer.
To put it simply, they aimed to see if it was possible to train non-experts using reinforcement learning into experts at (visually) detecting breast cancer cases. This pretty much wraps up the project background.
The Reinforcement Learning Procedure
The researchers first grouped the real-life non-expert agents into two groups. Group 1 received normal images at different levels of magnification, whereas group 2 received hue- and brightness-balanced monochrome images at different levels of magnification.
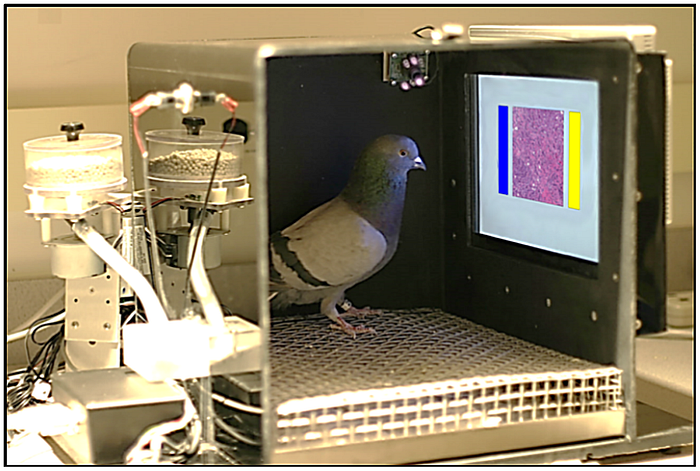
For the first few days, all agents were trained using picture slides that were shown to them on a touchscreen. The screen featured two binary options — benign or malignant (in simpler terms: cancerous or not cancerous). Each time an agent got the visual analysis right, the agent was rewarded (more on the reward mechanism later). Each time an agent got the visual analysis wrong, the same slide was flashed once more.
Results post trainig with breast histopathology samples (Image Credit: Levenson et al)
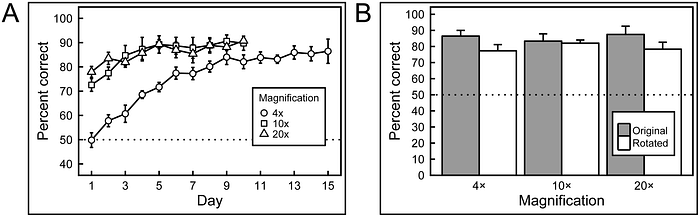
Once all agents showed logarithmic improvement in the visual analysis of the histological and mammogram images, they were tested using variations (rotations) of the same image set. From this phase onward, all agents were rewarded regardless of whether they got the analysis correct or wrong. This was done to stop the ‘learning phase’ and study the ‘performance phase’.
Finally, each agent was subject to a novel image set that was not part of the training image set. The novel image set was considered to be significantly difficult and was prepared under the supervision of experts.
In addition to this general procedure, the researchers tested further subtleties such as the effects of image treatment (brightness-/hue-) levels and image compression.
The Results — Novice to Expert in 15 Days?
All agents involved started with a success rate of around 50% (on par with mere chance). By the fifteenth day, they achieved a success rate of around 85%. This accomplishment did not exactly put them on par with experts but was good enough to put them in a comparable range.
Further testing (beyond the first 15 days) revealed that the agents were able to show comparable performance (to the experts) as both pathologists and radiologists.
The only situations where there was a significant performance dip were with novel mammogram datasets and when image compression was involved.
Based on these results, can we conclude that reinforcement learning can be employed to train cheaper non-experts into experts for the purpose of developing medical technology? Before we answer that question, there is a key detail that I have deliberately kept from you until now. We need to look at this key piece of information before we can make any conclusions.
The Catch
Remember when I told you that I will be sharing more information about how the agents were rewarded later in the article? Well, it is actually time for that now. Each time an agent got the analysis right, the agent was rewarded with seeds. That’s right; seeds! But why?
That is because these real-life intelligent agents were not human beings. They were pigeons. You might be fuming at me for having kept this key piece of information from you until now. But I chose to deliberately do so to demonstrate our distorted association of the word ‘intelligence’.
We associate intelligence with adjectives such as ‘human intelligence’ or ‘artificial intelligence’. It seldom occurs to us that there also exist other forms of intelligence such as ‘animal intelligence’ or ‘pigeon intelligence’.
The researchers chose pigeons specifically for this project because of their comparable optical processing systems to human optical systems. At the end of the project, the results showed that reinforcement learning could be used to train pigeon agents to detect cancer with a success-rate comparable to human experts.
The agent’s training environment (Image Credit: Levenson et al)
What’s more, when the researchers averaged the results from all agents to utilize “flock sourcing”, they success rate jumped further closer to the human experts.
What Does this Mean for the Future of Reinforcement Learning?
With extensive mathematical and computational research in the field of machine learning and reinforcement learning, there is no doubt that humanity is taking advantage of the latest computational capabilities available.
However, what this science project shows us is that there are other processing options available to us. The computers used to model intelligent agents need not be digital. We could use nature’s diverse manifestations of intelligent agents (within ethical bounds, of course) to further develop practical solutions for our advanced day-to-day problems using methods such as reinforcement learning.
Although the researchers in this science project managed to establish the significance of pigeons as potential agents for reinforcement learning, they did not get into the mechanics of what exactly enables pigeons to not just memorize training datasets, but generalize learning to unseen novel datasets as well.
Understanding how natural agents learn (in the context of specific datasets) could be an area of research for the future.
To conclude, it is both refreshing and promising to see such novel approaches to reinforcement learning beyond the fields of mathematics and computer science.
Credit/Source: Levenson et al. (scientific research article).
I hope you found this article interesting and useful. If you’d like to get notified when interesting content gets published here, consider subscribing.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.

Comments