How To Benefit From Computer Science In Real Life? (III)
Published on June 15, 2022 by Hemanth
--
In my previous essay on how to benefit from computer science, I covered the concept of time-space-money (resource) trade-off. In this essay, I will be covering the concept of ‘sort and search’.
We will begin by covering one of the most fundamental real-world applications of sort and search algorithms. Following this, we will transition into some of the fundamental challenges that these algorithms face and how computer science helped solve them.
Finally, we will look at the inner workings of one of the most efficient sort and search algorithms used widely today. Let us begin.
A Classic Real-World Application of Sort and Search
Pretty much as soon as books were invented, the need for sorting and storing books in a retrievable way popped up. In the not-so-distant past, books were expensive goods and the common man turned to the blessing that was the library to improve his knowledge.
As huge libraries housed thousands of books, sorting and storing the books in such a way that they were easily searchable and retrievable was key.
Before we look at how libraries actually solved this problem, let us try and solve it ourselves with a smaller number of books. There are certain key insights we could gain from this exercise.
How to Benefit from Computer Science to Sort and Search Books
Let us say that you have a total of 15 books, each featuring a title that starts with a different English alphabet. In order to store these books, you have one rack in a shelf available to you.
Given these conditions, how could you sort and store these books in a search-efficient way?
One idea that comes directly to mind is to store these books in alphabetical order of the first letter of their titles. If we do this, we would have a predictable way of storing the books in a single rack.
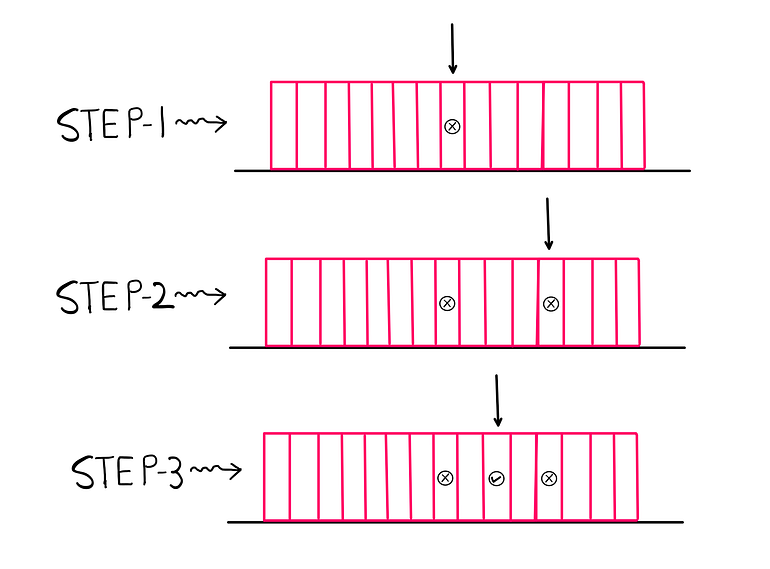
The next part that we need to figure out is how we should go about searching for a specific book. Lo and behold, there exists a very convenient algorithm for this purpose that we could steal from the world of computer science. Say that you are interested in locating a book that starts with the letter ‘S’.
Here is how the algorithm works: you pick up the center book and check its title. If its title starts with a letter that appears before ‘S’ in the English alphabet, you could safely reject first half of the rack (because your target book is sure to be in the second half). On the other hand, if its title starts with a letter that appears after ‘S’ in the English alphabet, you could reject the second half of the rack.
Illustration created by the author
In this case, let us assume that the book in the middle starts with ‘H’, which comes before ‘S’. So, you choose to reject the first of the rack. Now, you repeat this process for the book at the middle of the second half. Let us say that this book starts with ‘V’, which comes after ‘S’. So, this time, you reject the second half of the (original) second half and focus on the (new) first half.
After you repeat the process one more time, you arrive at the book that you were looking for. It happened to be at position number 10. The cool thing about this algorithm is that you needed to look at the cover of just 3 books out of 15 to locate your preferred book. This is brilliant, but what if we have more than 15 books?
Sort and Search Algorithm for ’n’ Number of Books
This might sound like a bit of an anticlimax, but we could use the same algorithm we just used to locate any book out of ’n’ number of books. The beauty of this algorithm is that it is smoothly scalable.
The key point to note about this algorithm is that each search attempt enables us to slash our search space in half. So, for 15 books, we would have need at most 4 searches to locate any specific book. Similarly, we would need to search (at most) only 5 times to locate any book out of 31 books, 6 times for 63 books, and so on.
In its generalized form, this algorithm requires us to search ’n’ times to locate any book out of a total of [(2^n)-1] books. If you do the math, it takes just 20 searches to locate any book out of 1,048,575 books. That is efficient! However, what if we wanted to locate a book by its author’s name?
The Library’s Solution for Sort and Search
The approach we have followed until now is very efficient, but it allows for searching using only one search criterion (title name). If we wish to accommodate search using other search criteria (such as author’s name), we will need to add more dimensionality to the sort.
But how is this physically possible? You have just one rack to order your books. You cannot sort your books based on more than one criterion.
Well, the libraries of the past came up with an ingenious solution for this problem. They used something called a “catalogue card” per book. This card contained the necessary information about the book such as author’s name, publication, etc., and included the location of the book as well.
The whole stack of catalogue cards was sorted based on the preferred criterion and stored separately. So, while the books were stored as per a different sort criterion, the catalogue cards enabled searching based on other criteria possible. All the library had to do was to create a new stack of catalogue cards for each unique criterion.
As efficient as this system is, when computers came into the game, they changed everything!
How Computers Transformed Physical Sort and Search
When modern computers became mainstream, they significantly reduced the cost of indexing. Without the need for physical catalogues, any search criterion that was to be used more than twice was likely indexed. Searching indexed content was orders of magnitude faster than sequentially searching non-indexed content.
Illustrative art created by the author
A modern library offers its users an array of options to search on. However, the fascinating part about this story is that it is not over yet. While digital cataloguing changed the playing field some forty years back, another aspect of storage is transforming how sorting works these days.
Modern Large-Scale Storage (Random Stow)
Computers use indexing for searching all the time. Since moving bits around on a physical storage is a relatively costly operation, the smart folks designing computers eventually figured out that it is not necessary to move data around on the physical storage all the time. It was sufficient to just update the index records with the latest location of the data you are searching for.
It sounds so obvious when I tell this story in the context of computer science. But what if I told you that the latest sort and search technology in big libraries has eliminated the ‘sort’ part completely? In other words, books are stored in random. A good example of this is the Hunt Library bookBot in North Carolina.
This system is so efficient that large scale direct-to-consumer delivery giant Amazon uses a very similar approach. Amazon does not waste time sorting items that belong to a group. Instead, any individual item is just stored randomly at the nearest available space, but is at the same time promptly indexed. Then, the index is used to locate the item later when it is time for shipment.
Final Remarks
We started by coming up with an algorithm to sort 15 books in a rack. Then, we scaled this algorithm to any number of books. Following this, we expanded the dimensionality of our sort and search solution to more than one search criterin using the age-old library trick of cataloguing.
Finally, we saw how computerized indexing enables us to completely eliminate sorting to improve search efficiency. The only downside of this approach is that it makes us pretty much 100% dependent on computers. It is not a system that would be sustainable if there was a database failure or server crash.
Let us say that you wish to benefit from computer science for a physical sort and search application whilst avoiding dependency on computers. In this case, it might be worthwhile to sacrifice some efficiency by avoiding random stow and sorting the items physically and storing them.
If you’d like to get notified when interesting content gets published here, consider subscribing.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.



Comments