Ergodicity: The Hidden Reason For Society’s Growth And Your Misfortune
Published on October 14, 2022 by Hemanth
--
Ergodicity is one of the most counter-intuitive concepts that I have come across in recent times. It is a complex-sounding term for a relatively simple phenomenon (we’ll see what it is about shortly). Yet, it is the consequences of ergodicity that catch us (human beings) off guard.
Imagine that you live in an economically flourishing country. The Gross Domestic Product (GDP) has been steadily on the rise for the past years. Yet, your salary has not been increasing proportionally.
As you ask around, you realise that none of your friends’ salaries has risen significantly either. How can this be? Where is all the money realised from this economic growth headed?
Well, the answer to the question of ergodicity says that the more your country’s economy grows, the lesser the average resident/worker earns! That sounds like nonsense, right? Well, I assure you that it is not. Let us find out how.
I plan to keep this essay as simple and approachable as possible. However, there are a few technical terms we need to touch upon as prerequisites to understanding ergodicity. But fear not, they are relatively simple concepts with complex-sounding names (scientists like doing that for some reason).
Here is the short list of terms we are about to cover:
1. Expected value (probability theory).
2. Stochastic processes and stochastic models.
3. Frequentist probability.
What is Expected Value?
If you are interested in a proper in-depth discussion on this topic, check out my dedicated essay on expected value. If you are in a hurry, here is a dumbed-down version that is sufficient to make sense of the discussion in this essay:
We compute the expected value of any bet by multiplying the numerical value of each possible outcome with its probability and summing up all such terms.
For example, if you bet $1 on a fair coin toss, we can compute your expected value of the bet as follows:
Expected value = [(Probability of win)*(Outcome of win)] + [(Probability of loss)*(Outcome of loss)]
= [½ *(2)] + [½ *(0)] = $1
So, you can expect to neither gain nor lose if you played this game repeatedly a significant number of times. Now, onward to stochastic processes we march.
Stochastic Processes and Models
Any process that involves a random variable whose value changes with time is stochastic. Examples would be how your blood pressure or income varies with time. The random variables here are blood pressure and income respectively.
Mathematicians have figured out clever ways of modelling such processes using mathematical equations. These models are then used for predictive decisions. We refer to such models as stochastic models.
Of course, this is a deeply technical subject. But this level of understanding suffices the purposes of this essay. So, we move on to the notion of frequentist probability next.
What is Frequentist Probability?
Frequentist probability treats the probability of an event as the frequency with which it occurs when we repeat the contextual trial a (sufficiently) large number of times. This probability value has to converge and this behaviour, in turn, is described/governed by something known as the law of large numbers.
Here is a practical example: if we keep measuring the heights of a large enough set of human beings, we can eventually compute the probability of (and thus predict) how tall any given human being is likely to be.
This concept is more intuitive than you probably think it is (see what I did there?). For instance, if I told you that I saw a human being 2 Kilometres tall, you would immediately call me out as a liar. Why? The reason is you have an intuitive frequency distribution of human heights based on your life experience (empirical observations).
Of course, you cannot put a precise number on the probability. But you can roughly estimate the ranges; 2 Kilometres is well outside this range. That is pretty much the intuition behind frequentist probability.
Again, this topic can get really complex. But this level of intuition is sufficient for us. So, finally, we set out to meet this “ergodicity” thing that has enticed us into this journey.
The Question of Ergodicity
Although we have had to cover a few technical prerequisites, the question of ergodicity itself is ironically simple:
For any given stochastic process, is the expected value (average) of a large number of occurrences in a single instant of time equal to the expected value (average) of a single random variable over a very long duration of time?
If you find this confusing, let me rephrase the question using a practical example. Suppose that a drug manufacturer announces that their latest cancer drug is 85% effective on average in curing the disease. Then, the following is the corresponding question of ergodicity:
Does the drug cure cancer in 85% of the patients 100% of the time? Or does the drug cure cancer 85% of the time in 100% of the patients?
If the answer to both these questions converge on one answer (that is, if both are equal), we call the stochastic process ergodic. Otherwise we call it non-ergodic. Do you see the challenge here?
If not, let me elaborate. We cannot tell which stochastic process is ergodic just by looking. But we intuitively assume that all stochastic processes are ergodic. Therein lies the issue. But before we understand this issue deeper, let me tell you a little bit about the origins of ergodicity.
The Origins of Ergodicity Theory
While ergodicity finds its deep roots in probability theory, its practical application stems from a surprisingly unlikely field: physics! More specifically, it emerges from statistical physics.
As physicists were trying to model gas dynamics using statistical data, they had to choose between the time average and the ensemble average. That is how ergodicity theory established itself in scientific society.
Little did the physicists know back then that this concept applies to many more phenomena/fields than just physics. I got to learn about ergodicity theory first from the work done by Murray Gell-Mann and Ole Peters.
Their work had such controversial repercussions that initially, journals and scientific peers posed heavy resistance. But as they say, merit eventually finds its way. After publishing their work in a lesser-known journal, it transformed the scientific outlook on economics. And ergodicity was at the heart of that discussion.
The GDP Vs. Salary Discussion
We are now ready to continue the discussion that we started in the introduction of this essay. Why is your salary not increasing while your country’s GDP surges? Well, the GDP is an ensemble average of many, many random variables (people) in a single instance of time whereas your salary is a time average of a single random variable (your salary).
GDP Vs. Salary — Illustrative art created by the author
Let me explain what’s going on with an example. Assume that we assign 1000 professional gamblers with positive drift/advantage to a casino. At any given point in time, you can expect our gamblers (ensemble) to make some money on average. Some gamblers would have gone bust, but your ensemble average would still be a net positive.
However, if you pick any single gambler and consider your expectation of his/her/their profit over an infinite time frame, you would land on the number “zero”. This is because as long as the risk of ruin (probability of complete wipeout) is non-zero for any gambler, it is bound to occur.
We land upon a very counter-intuitive realisation that any single gambler is likely to go bust over time, but at any instant of time, the average performance of all gamblers is a net positive. Does that sound familiar?
Well, that’s how the average salary of a country’s worker might go down while the GDP surges. But hang on, just where is all this growth money going?
Power Laws Rule an Unfair World
I am sure you have heard of Vilfredo Pareto, the guy after whom the Pareto distribution is named. This distribution belongs to a family of distributions which come under the general term power law. The characteristic feature of these distributions is that they are skewed and have long tails (it is not a must that you understand these terms).
In simpler terms, phenomena that follow power law distributions are not easy (if not, impossible) to predict. In even simpler terms, the term “average” often loses usefulness in the context of power laws.
To illustrate this fact, let us consider the following situation. You have measured the heights and computed the average height of a sample size of 100 human beings. If you add the tallest human being to this list, the average is likely to move (at best) only a few inches. In other words, we can still make use of this average.
Now, imagine that you have computed the average income of 100 human beings. Next, I add Elon Musk to this list. All of a sudden, your average is going to surge so high that 100 of 101 people are going to perform well below average. At this point, what use does such an average serve?
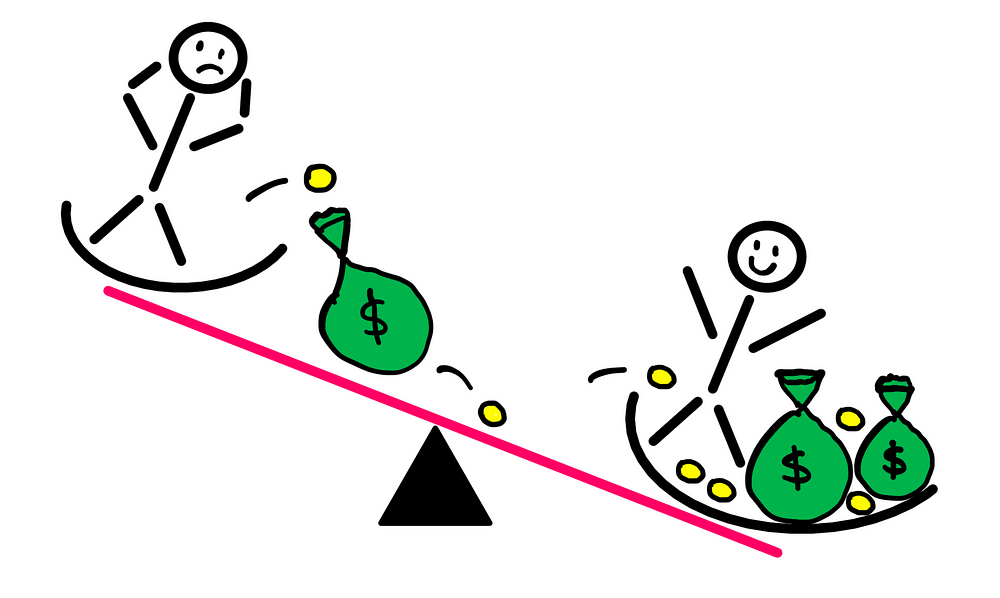
Rich vs. Poor Seesaw: Illustrative art created by the author
In any case, all that GDP growth money flows into the hands of a very, very small number of long-tail winners. I’m merely stating this as a mathematical observation; it is a natural consequence of multiplicative dynamics. Make of it what you will.
Final Thoughts
I have barely scraped the surface of ergodicity theory in this essay. In reality, it is indeed a very technical topic. But I thought that basic awareness of this phenomenon would serve well for any intellectual when it comes to making practical life decisions.
We can apply ergodicity theory to any phenomenon that features multiplicative growth. Examples of such phenomena are best-selling books, top music charts, drug/vaccination development, etc.
This essay is actually the follow-up to my essays on varianceand St. Petersburg paradox. So, if you found this essay useful, I would highly recommend that you read the precursors as well.
To wind up, here are three points you can take away from this essay:
1. Whenever you are dealing with random variables that vary with time (such as revenue, industry average, etc.,), pose the question of ergodicity.
2. When dealing with investments, bets, etc., ask yourself if your “expectation” is based on time-averaging (historical performance) or ensemble-averaging (how your friends’ portfolios are doing).
3. Whenever you hear/read words like expectation or average, be more sceptical and look for clarification on what exactly they mean. These terms are generally a big source of misunderstanding. So, exercising healthy scepticism might save you from making poor life decisions.
Duerfte ich Sie darum bitten, dass Sie alle meine Tweets-Threads, besonders meinen Pinned-Tweet-Thread, baldigst lesen? Denn das Weltende = ein globaler Kernkrieg ist sehr sehr nahe, weil nun jede Hackers frei die Nuclear-Missile-Silos usw. hineinhacken mit den Mathe-Techs zum RSA-/etc.-Codes-Brechen, die ich in meinem Pinned-Tweet-Thread gesammelt habe.
Pls search Twitter under the keywords of “@koitiluv1842 RHT” (in which RHT means Riemann Hypothesis Theorem that facilitates RSA-codes crackings/breakings).
But to view all my tweets in each of my tweets, pls click all my tweeting dates, bc Twitter.com hide many of my indispensable-info-containing tweets.
Thank you for your interest in my work, and thank you for your response as well. I will take my time to read your work and respond. It might take some time for me to respond, but I will surely respond.
P.S.
I have now added Japanese as a language offering on Street Science. So, you would be able to read the content automatically translated to Japanese if you prefer it so.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.



Excuse me. I am a Japanese amateur economics-researcher. May I take the liberty of entreating you to look over my related tweets-threads proving the Marxian Workers-Class’s Absolute Pauperization Law (= das Absolutverelendungsgesetz), please?:
https://twitter.com/search?q=%40koitiluv1842%20Pauperization&src=typed_query&f=top
Duerfte ich Sie darum bitten, dass Sie alle meine Tweets-Threads, besonders meinen Pinned-Tweet-Thread, baldigst lesen? Denn das Weltende = ein globaler Kernkrieg ist sehr sehr nahe, weil nun jede Hackers frei die Nuclear-Missile-Silos usw. hineinhacken mit den Mathe-Techs zum RSA-/etc.-Codes-Brechen, die ich in meinem Pinned-Tweet-Thread gesammelt habe.
Correction:
Pls add “koennen” after “hineinhacken” above.
Excuse me for bothering you again.
Pls search Twitter under the keywords of “@koitiluv1842 RHT” (in which RHT means Riemann Hypothesis Theorem that facilitates RSA-codes crackings/breakings).
But to view all my tweets in each of my tweets, pls click all my tweeting dates, bc Twitter.com hide many of my indispensable-info-containing tweets.
Re-correction:
Read “each of my tweets” as “each of my threads”.
Dear Mr. Koiti Kimura,
Thank you for your interest in my work, and thank you for your response as well. I will take my time to read your work and respond. It might take some time for me to respond, but I will surely respond.
P.S.
I have now added Japanese as a language offering on Street Science. So, you would be able to read the content automatically translated to Japanese if you prefer it so.