In information theory, entropy is a measure of uncertainty. It lies at the heart of some of the most fundamental computer science concepts such as the unit of information (bit) as well as advanced applications such as data compression (zip files), password protection, etc.
Since the concept of information goes beyond the world of computers, I often find myself applying my knowledge of entropy to a wealth of real-life applications. So, I thought it would be a worthy topic to cover in its own series.
In this essay, we will begin by understanding the notion of entropy with the help of simple examples. For this purpose, the only prerequisite is that you are familiar with fundamental probability theory concepts. Without any further ado, let us begin.
Let us say that I flip a fair coin and ask you to guess the outcome. Although the outcome is “uncertain”, you and I can be “certain” that there are only two possible outcomes: Heads (H) or Tails (T).
In the world of computers, the outcome (H or T) can be represented by a single binary digit (known as bit). In other words, one bit captures the level of uncertainty in the outcome of a single fair coin flip.
But why stop there? Let us keep going. What happens when I flip two fair coins simultaneously and ask you to guess the outcomes in a single instant. This time, we have four possible outcomes: HH, HT, TH, TT.
Your choice would inevitably be one of the four. Consequently, you have one in four chances of getting the outcome right. With that, we enter the world of probability theory.
The Precursor to Entropy: Measuring Information
Suppose that we wish to measure the uncertainty in your knowledge (measured in information) when approaching this game. When I flipped one fair coin, you had one in two chances of getting the outcome right.
When I flip two fair coins simultaneously, you know that you have one in four chances of getting the outcome right. In information theory, we measure the uncertainty in this information (your knowledge) using the following mathematical expression:
Measuring uncertainty (information) — Math illustrated by the author
We know that P(E) = 0.5 (or 50%) for the first game, and P(E) = 0.25 or (25%) for the second game. Accordingly, we can compute/measure the uncertainty in your knowledge of both games as follows:
I(E) for single/double coin toss — Math illustrated by the author
Understanding the Mathematical Expression for Information
The reason we divide 1 by P(E) is to reflect the following fact: the higher your probability of getting the outcome right, the lesser the uncertainty you deal with (and vice-versa).
For example, if I flipped 20 coins, you “know” that there are 2²⁰ possible outcomes and you can only guess one outcome combination out of that set. This makes the outcome very unlikely.
Furthermore, the reason we use the logarithm is twofold:
1. To model a saturation that is characteristic of all human beings, wherein, the more we know, the less we value the knowledge. In other words, information has diminishing returns for us.
2. We can measure large quantities of information on a scale that is intuitive to us. Our intuition somehow works better with smaller numbers as compared to very large numbers. This way, we can still make sense of the odds of one in ten on the same scale as one in ten billion.
Finally, the reason why we use base 2 logarithm is that computers work using binary digits (0 and 1); so we can directly get the measure in bits.
Now that we know how to measure information as uncertainty in our knowledge for particular outcomes, we may proceed to entropy.
A Slot Machine with Very Low Odds
So far, we have been measuring the uncertainty in your knowledge (information) for the event that you win. If we invert the situation and try to measure the uncertainty in your knowledge for the event that you lose (that is, your guess is wrong), we would get the same numbers as above.
This is because we are dealing with a fair coin. So, both outcomes (win or loss) are equally likely. Now, I change the situation and present you with a slot machine where you have a 1 in 1024 probability of winning (I explicitly tell you this; so you can consider this your knowledge).
As you play the slot machine, “you know” that there are only two possible outcomes: you either win or you lose. Consequently, we can compute the uncertainty in your knowledge for the events of winning and losing as follows:
I(W) and I(L) — Math illustrated by the author
The results we have confirm what we know so far. The more uncertainty an event features, the less likely it is to occur.
You know that “losing” is the most probable outcome, so there is very little uncertainty in knowledge (information) about it. We knew this intuitively before, but now we have managed to put a number on it (0.00141 bits approximately).
Entropy: How to Measure Uncertainty
Entropy is nothing but the average or the expected value of uncertainty in knowledge (information) of all possible outcomes of a random event.
For the slot machine, we would compute the entropy as the probability of winning multiplied with the uncertainty of winning summed up with the equivalent computation for the event of loss. Mathematically, it would be as follows:
Entropy H(E) — Math illustrated by the author
When we are dealing with the notion of expected value, we have to be very careful. I have covered this topic in a dedicated essay. If you are interested, check it out. For now, let us focus on the fact that the entropy for the slot machine is a fraction of a bit (not a whole).
How are we supposed to make use of this when the lowest unit of measure of information for a computer is 1 bit?
Well, what this number really means is that in order to convey the outcome of this game, there is a very small chance that we need ten bits and a very high chance that we need less than a bit.
In other words, to make use of this entropy, the event that we are tracking/measuring needs to be repeatable or repeating itself sufficient number of times for the law of large numbers to take effect. This brings us to how we can use entropy.
Applications of Entropy
Literally ALL of the information that I have presented to you in this essay came from one person’s master thesis: Claude Shannon. I’m still in disbelief that one single (young) person contributed so much to a field (to be fair, his work founded information theory in the first place).
Let us say that in the case of the slot machine, we had previously allocated 10 bits of information to convey the result of each game to each player playing the game. What Shannon figured was by measuring entropy (also known as Shannon entropy) of events/systems, we need not allocate 10 bits each for each game.
In fact, we could configure the slot machine such that it conveys information only on the occasion of a win. This way, in Shannon’s terms, we maximise the information channel and minimise the resources used.
This concept was so revolutionary that until this day, it is used in compression algorithms, password protection/encryption algorithms, error correcting codes, etc.
I will cover some of these interesting topics in future essays. But for now, I hope you enjoyed the fundamentals of entropythat I presented in this essay!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.



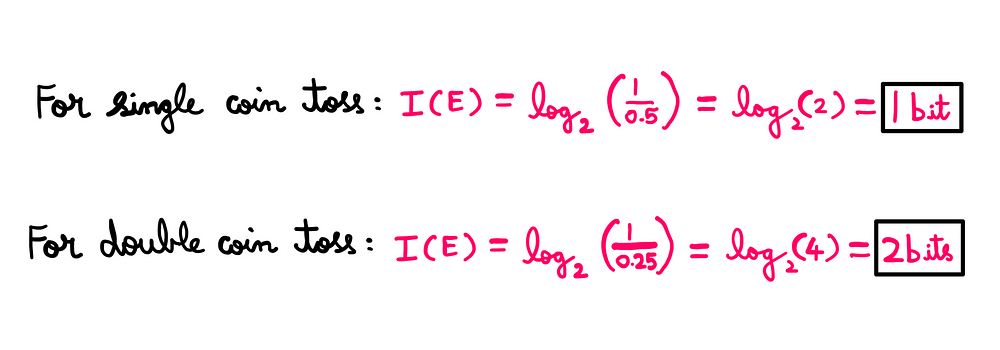
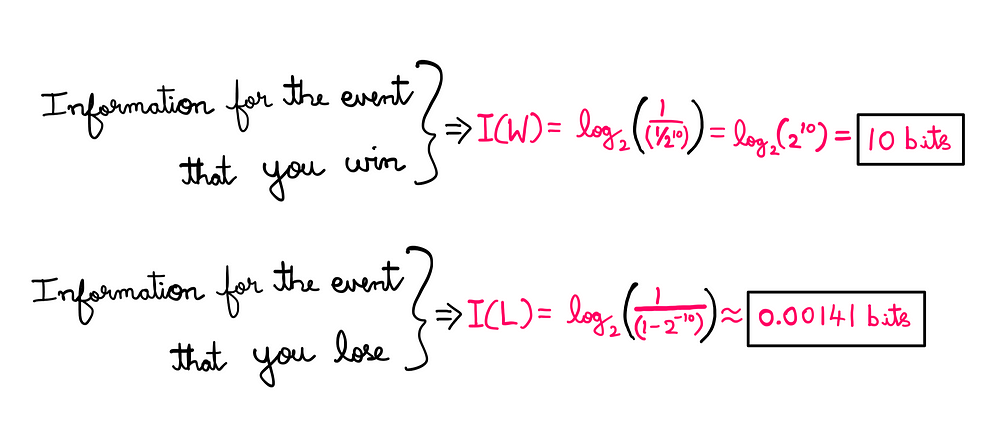
![Entropy: How To Actually Measure Uncertainty -White board graphics presenting the following information: H(E) = P(W)*I(W) + P(L)*I(L) = [(1/2¹⁰)*10] + (1–2^(-10))*0.00141 = 0.011174 (approximately)](https://cdn-images-1.medium.com/max/1000/1*YVQ66QzqngICZhA60yBniA.png)
Comments