Correlation: One Of The Most Misunderstood Concepts In Science
Published on September 5, 2022 by Hemanth
--
Be it the medical sciences or the social sciences, correlation is at the heart of scientific discovery. Say that you wish to invent a new drug to cure a disease. You could just gather a bunch of bio markers that have a positive correlation with curing the said disease.
Then, you just test plausible chemical combinations that aid this said “positive correlation”. Trial and error is your friend. At some point, you should have a new drug that cures the disease.
Now, say that you wish to analyse if the price of your new drug would have any effect on your company’s stock market price or vice-versa. You perform a “linear-regression” analysis comprising the two variables (based on some past data).
This is standard practice in the biz, and your analysis shows that the price of your drugs and your company’s stock market price are uncorrelated. So, you could go ahead and price your latest drug without consideration to your company’s stock market price. Pretty cool, right?
Well, not quite. The results of your drug development method as well as your linear regression analysis might be misleading you . And your misunderstanding of the word “correlation” is to blame.
This essay aims to correct that. We will be starting with the history of how correlation was discovered. Following this, we will swing back and forth between regression and correlation with a slight touch of analytic geometry.
It would help you if you have already read my essay on regression. At the end of this essay, you should have a better understanding of both correlation and regression. This, in turn, would help you avoid the common pitfalls. Without any further ado, let us begin!
Our story begins with the renowned polymath, Francis Galton. Among his many adventures, he was studying the nature of heredity. He had already figured out that children of tall parents tended to be taller than average, but still shorter than their parents.
On the other hand, children of short parents tended to be shorter than average, but still, taller than their parents. Galton termed this phenomenon ‘regression’. In essence, he had discovered regression to the mean.
But he wasn’t satisfied with just that. He wanted to quantify the effect of regression. Clearly, it wasn’t just regression which decided a child’s height. Heredity also played a role. But how much did each affect the final height? That’s pretty much the question he was trying to answer.
Correlation — Galton’s Ellipse
Galton collected parent-child height data and created a table which featured a map between parents’ heights and adult children’s heights. I’m skipping the fine details here on how exactly he computed these, but this suffices for our requirements in this essay.
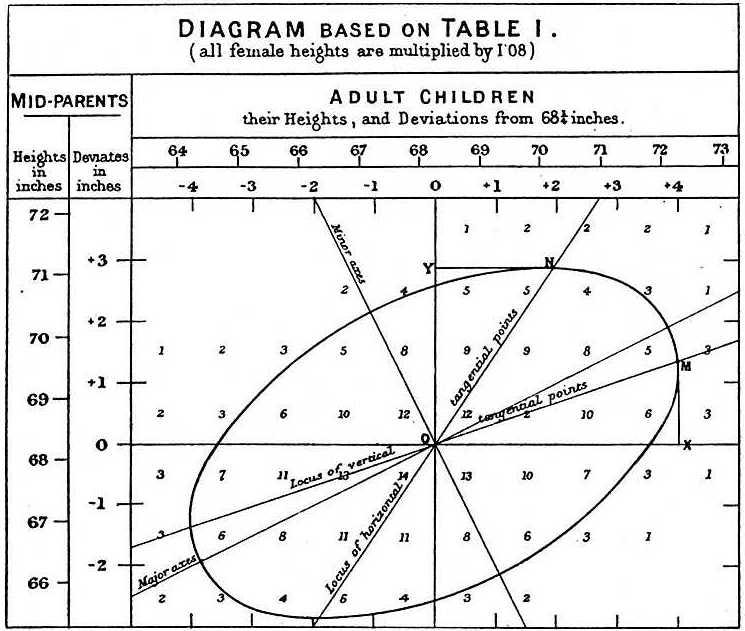
He noticed something peculiar. He began seeing an elliptical shape that did not appear random. Here is a diagram he published based on his data in his 1886 paper “Regression Towards Mediocrity in Hereditary Stature”:
This diagram reveals the interplay between heredity and chance. In the forthcoming section, we will briefly see how variations in both of these variables could affect this interplay.
Galton then decided to plot each parent-child height pair as a point in a two-dimensional plane; he considered parents’ heights on a horizontal axis and children’s heights on a vertical axis. Mind you, back then Cartesian graphs were not remotely close to the norm.
By doing this, Galton had in fact invented what we know today as scatter plots. While we are on the topic of scatter plots, why don’t we see how heredity and chance affect the outcome of the graphical results?
Introduction to Correlation via Scatter Plots
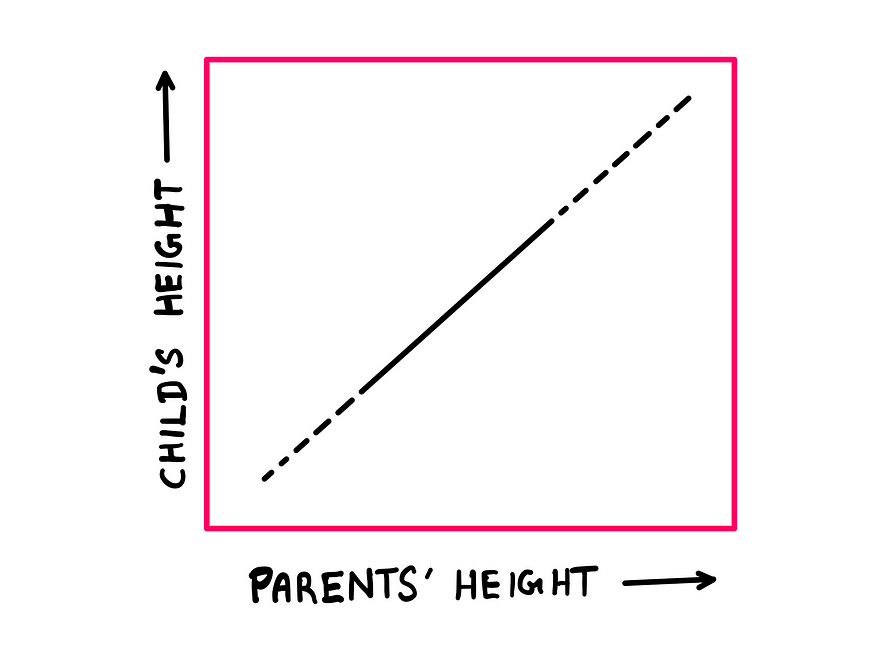
Let us now say that chance has no role to play in Galton’s parent-child dataset. In such a case, heredity governs the adult child’s height, and every child would be exactly as tall as the parent. In such a case, the scatter plot would look like this:
Scatter plot for fully deterministic behaviour — illustration created by the author
It is no wonder that we see just points along a diagonal line here, because we have a situation where (x = y). Having said that, note that the points are more scattered toward the peripheries than in the middle.
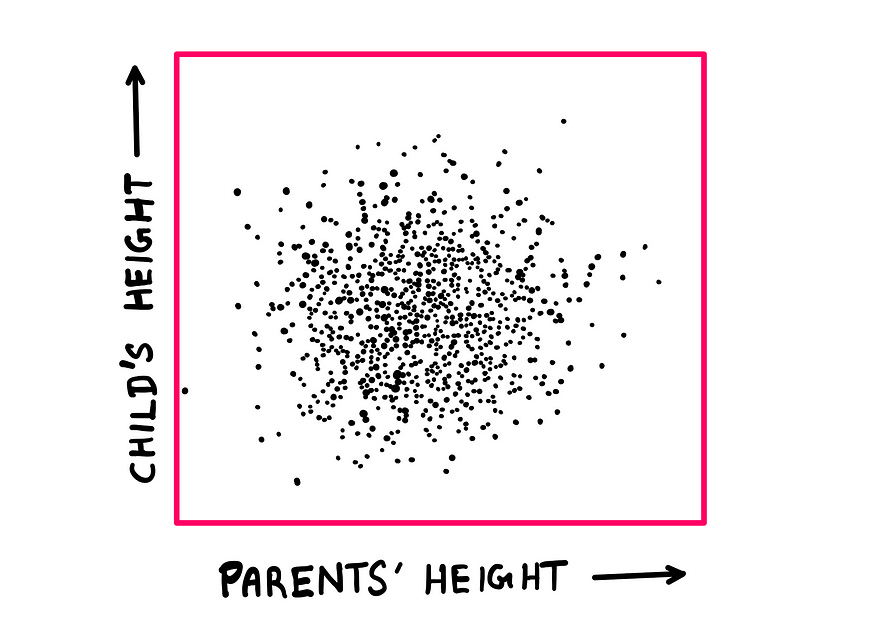
Now, let us say that heredity has no role to play in Galton’s parent-child dataset. In this realm, chance governs the outcome 100%. The corresponding scatter plot would look like this:
Scatter plot for completely random behaviour — illustration created by the author
This scatter plot shows no affinity to the diagonal. In other words, the child’s height and parent’s height are independent of each other. So, regardless of the parent’s genes, the child’s characteristics are 100% luck of the draw (chance).
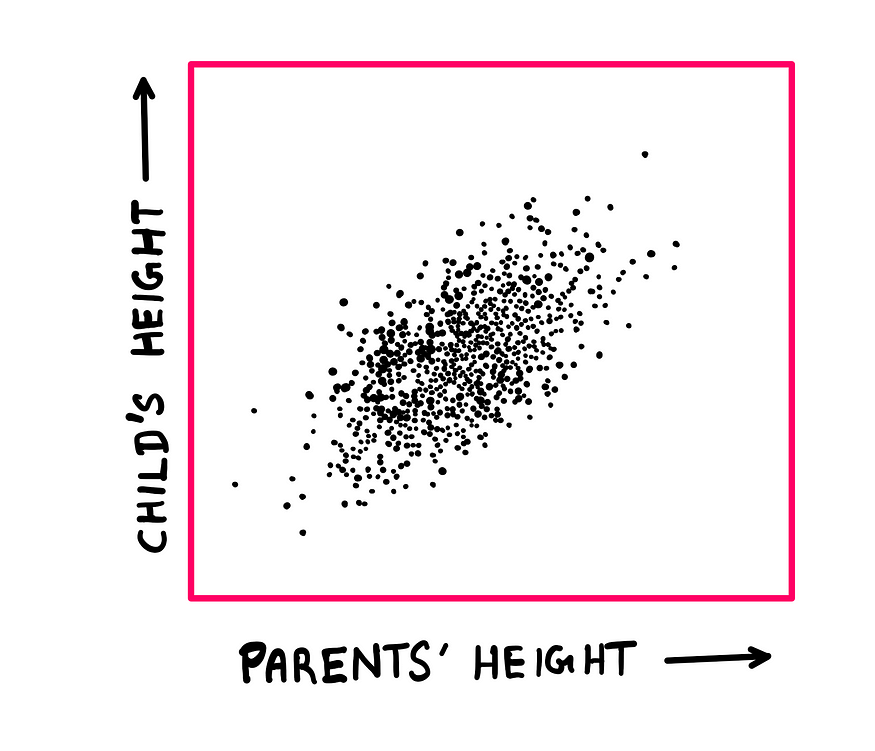
As you can imagine, both of these are extreme cases. The reality slots somewhere in between. Galton’s dataset led to a scatter plot that looked like this:
Scatter plot depicting Galton’s correlation data — illustration created by the author
Here, we can clearly see the ellipse from the left-hand bottom corner to the right-hand top corner. Galton was so methodical with confirming this result that he went to the trouble of concealing the data’s background (to remove prejudices) and consulting a mathematician to confirm his observation; old-school peer review, if you will.
Drawing Conclusions from the Scatter Plots
Comparing all three scatter plots, we could arrive at the following three empirical conclusions:
1. When the outcome is completely deterministic (that is, controlled 100% by heredity), the ellipse collapses into a straight (diagonal) line.
2. When the outcome is completely governed by chance, the ellipse expands to become a circle (roughly speaking).
3. When the outcome is governed by a mix of both, an ellipse of ‘some’ level of eccentricity results.
Galton termed the measure of this eccentricity (of the ellipse) correlation. Over time, the measure of correlation has been advanced by impressive contributions from people such as Karl Pearson. Today, we apply the concept of correlation to data-sets that span multiple dimensions (a topic for another day).
Back to our main challenge: Why are the methods you followed for your drug company misleading you? Let’s jump right into the answers.
Correlation: One of the Most Misunderstood Concepts in Science
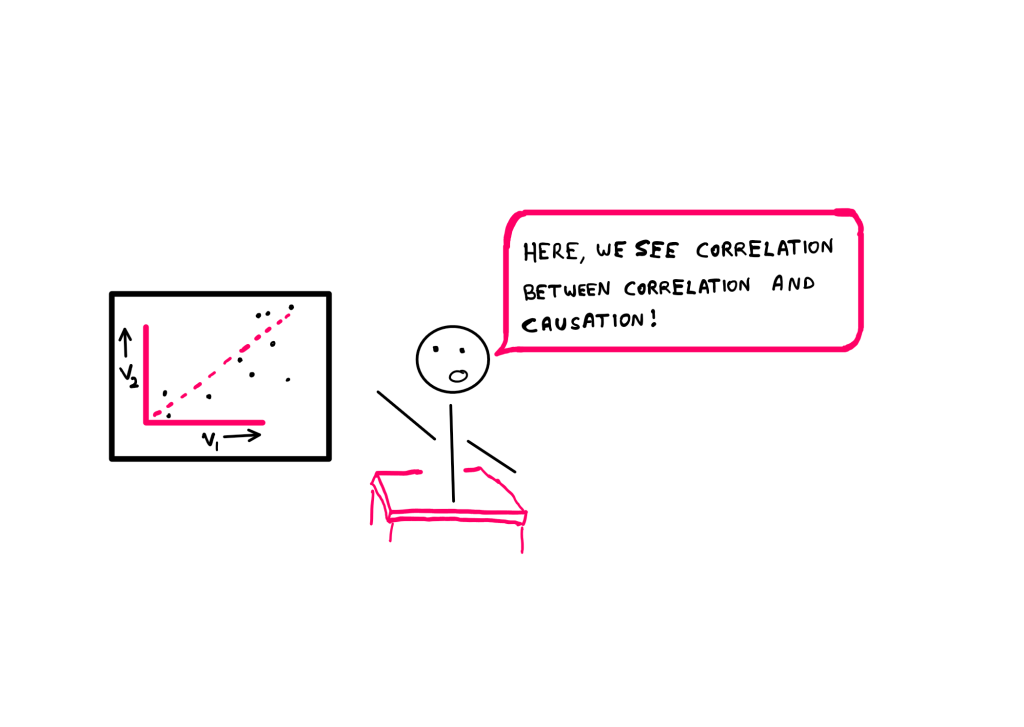
You might have heard of the phrase “Correlation does not mean causation”. This phrase has almost become mainstream. What it means is that two correlated variables need not necessarily have causal links.
For instance, it could be that the biological markers you have gathered are positively correlated with curing the said disease. However, it is NOT a given, that they are causally linked. In other words, having the required bio markers does not necessarily guarantee cure from the said disease.
Since this issue has become more or less mainstream, many researchers are able to wrap their heads around reading correlation information without imposing causal biases. However, the intransitivity of correlation is something that still catches many researchers off guard.
To understand transitivity, let us consider the following relationship: (a > b > c). From this, we see that ‘a’ is greater than ‘b’ and ‘b’ is greater than ‘c’. Based on this, we could say for sure that ‘a’ is greater than ‘c’.
This property of extending a relationship from one variable to another from the given relationship information is known as transitivity. “Greater than” relationships are transitive. However, correlation is NOT.
Here’s your situation: your new drug boosts the bio marker readouts. These bio markers are in turn positively correlated with the disease’s cure. Based on this, the intuitive conclusion many would make is that the new drug helps cure the disease. But you see, this is NOT a given.
To drive home this point, consider a child that prefers ice-cream ‘a’ to ice-cream ‘b’. The same child prefers ice-cream ‘b’ to ice-cream ‘c’. Does this mean that the child prefers ice-cream ‘a’ to ice-cream ‘c’?
Anyone who has interacted with an ice-cream-loving picky child would not make that “assumption”. But wait, there’s more!
Uncorrelated variables are NOT Always Unrelated
In the introduction, we saw that the price of your drugs and your company’s stock market price were uncorrelated. This might well be the case, but that does NOT mean that they are unrelated.
The dirty little secret of most of the regression/correlation analyses conducted in scientific research is that they look for linear relationships. This is a conceptual simplification. Not all relationships are linear, and not all uncorrelated variables are unrelated.
The non-linear relationship between your drug prices and your company’s stock market price could take you for a ride if your decisions do not take into account the possibility of these two variables “becoming” correlated in the future or beyond the realm of your data set.
A linear analysis that says two variables are uncorrelated simply says that they do not have a linear relationship. Many researchers still fall prey to concluding that the two variables in question are independent of each other.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
CookieLawInfoConsent
1 year
Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
_gat
1 minute
This cookie is installed by Google Universal Analytics to restrain request rate and thus limit the collection of data on high traffic sites.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
__gads
1 year 24 days
The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites.
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_ga_R5WSNS3HKS
2 years
This cookie is installed by Google Analytics.
_gat_gtag_UA_131795354_1
1 minute
Set by Google to distinguish users.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.

Comments